How to Build a ReAct AI Agent for Cybersecurity Scanning with Python and LangGraph

Introduction
ReAct agents are tricky to implement correctly, and in this article I will show how to do it using a cybersecurity AI Agent example that can find vulnerabilities in any provided web target. Today I will explain:
- How to use tokens efficiently in ReAct agents
- How to force ReAct agents to use tools efficiently and not be too lazy
Subscribe to my Substack to not miss my new articles 😊
Theory
Before we jump to the implementation, let's first define what an AI Agent is and how I can build it.
AI Agent
An AI Agent is a hot architecture pattern with LLM, loop, and actions (tools) that the LLM can perform. The LLM is used here as a brain that can decide what to do as a replacement for regular code that software used previously to make decisions.
Traditional automation breaks when conditions change. Agents adapt. That's the real value - resilience, not just "LLM with extra steps."
There is a very basic AI Agent architecture:
Loading...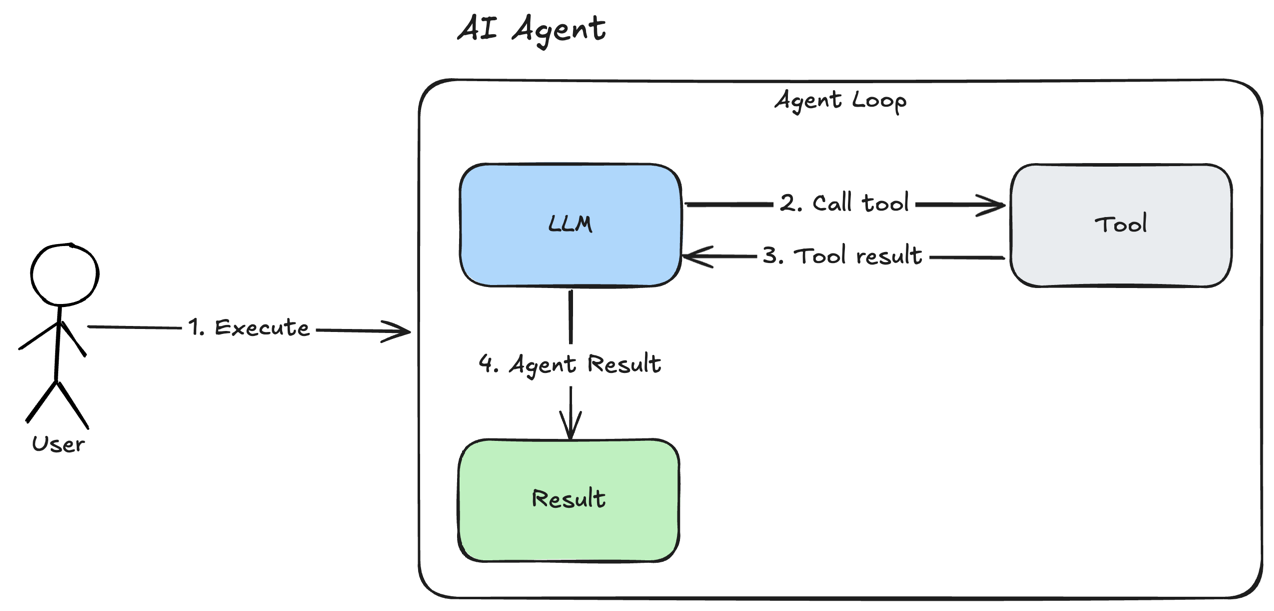
- User executes AI Agent
- LLM makes its own decision to call some tool to perform an action
- Tool returns a result to LLM and allows LLM to perform a new decision. This process loops until the LLM decides that a result can be provided to the user or certain conditions are met.
- LLM produces a final result for the agent.
AI Agents have different patterns used to build them, and for me they are similar to classic software patterns like Factory, Singleton, or Strategy. But in this article I focused on the simplest one - the ReAct pattern.
ReAct Agent Pattern
Loading...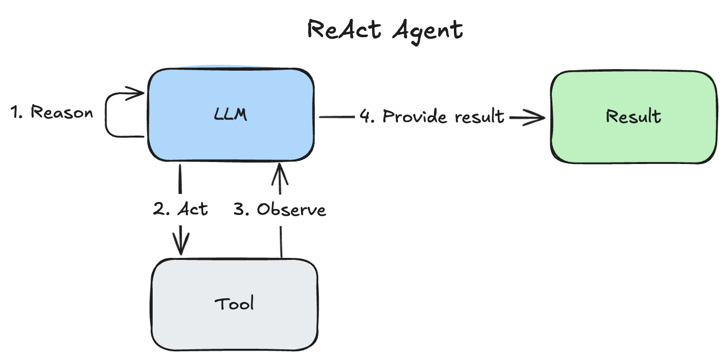
ReAct is a pattern for AI Agents with these steps:
- Reason - LLM thinks about data or tool results
- Act - LLM calls tools to perform some actions
- Observe - LLM handles results of tool execution
- LLM provides final result
Project Requirements
To learn how to build a ReAct Agent, I decided to build a vulnerability scanning AI Agent. It will accept a web service URL as input and provide a vulnerability report as output.
Loading...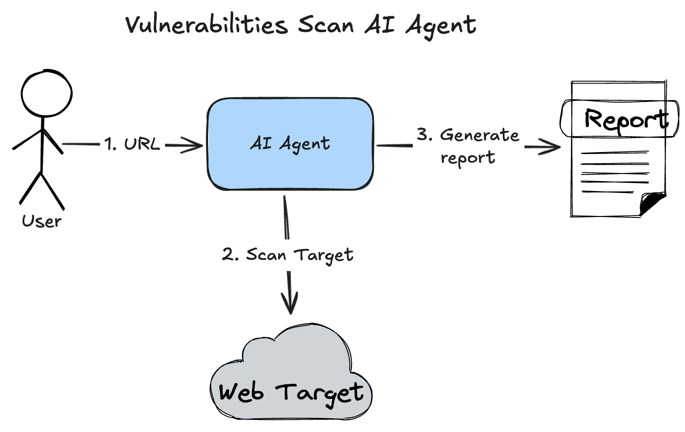
I used this technology stack to build it:
- Python
- LangGraph
System Design
Loading...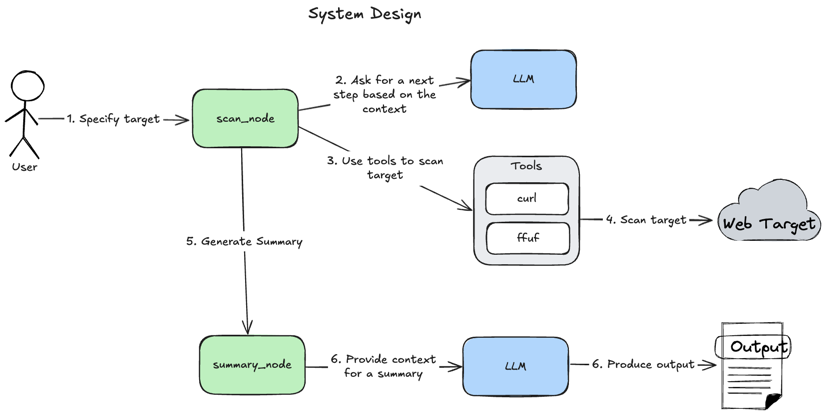
- User specifies a target to scan.
scan_nodeasks LLM to reason about context and make a decision about the next step.scan_nodeuses tools to perform Web Target scanning if LLM decides to do so.toolsscan Web Target.scan_nodecallssummary_nodeif LLM decides that no additional tool usage is required.summary_nodeprovides context about scanning results to LLM.- LLM produces summary output
So it's a basic ReAct pattern but with an extra node to perform summary generation. This approach produces a summary with higher quality rather than direct ReAct pattern result consumption.
Implementation
Short term memory - graph state
Code available on GitHub
To implement short term memory I used this graph state:
1class ReActAgentState(MessagesState): 2 usage: ReActUsage 3 tools_usage: ToolsUsage 4 tools: Tools 5 results: Annotated[list[ToolResult], operator.add] 6 target: Target
Which contains:
tools_usage- to track current tool usage and check if it doesn't exceed limits.usage- to track the depth of graph recursion execution and prevent reaching limits.tools- a dynamic list of tools that users can specify during graph execution, which makes this graph reusable.results- list of tool execution results used to reduce LLM token usage.
In the ReAct agent implementation, we are allowing LLM to call tools and LLM should parse tool results to perform a reason step to decide what to do next. The problem with the default approach in LangGraph:
- Call tool.
- Receive tool result as a message.
- Perform reasoning
This history of tool executions is saved until the current execution of the graph reaches the end. This makes token usage enormously high. To reduce it, I decided to save current tool execution in the state.results field and pass to LLM only when it's needed and not on each LLM call.
Common node - ReActNode
Code available on GitHub.
This node inherits from the common ReAct node which I introduced to omit duplicate work in the future:
1system_prompt = """ 2You are an agent that should act as specified in escaped content <BEHAVIOR></BEHAVIOR>. 3 4TOOLS AVAILABLE TO USE: 5{tools} 6 7TOOLS USAGE LIMITS: 8{tools_usage} 9 10TOOLS CALLING LIMITS: 11{calling_limits} 12 13PREVIOUS TOOLS EXECUTION RESULTS: 14{tools_results} 15 16<BEHAVIOR> 17{behavior} 18</BEHAVIOR> 19""" 20 21 22class ReActNode[StateT: ReActAgentState](ABC): 23 def __init__(self, llm_with_tools: Runnable[LanguageModelInput, BaseMessage]): 24 self.llm_with_tools = llm_with_tools 25 26 def __call__(self, state: StateT) -> dict: 27 prompt = system_prompt.format( 28 tools=json.dumps(state["tools"].to_dict()), 29 tools_usage=json.dumps(state["tools_usage"].to_dict()), 30 calling_limits=json.dumps(state["usage"].to_dict()), 31 tools_results=json.dumps([r.to_dict() for r in state.get("results", [])]), 32 behavior=self.get_system_prompt(state), 33 ) 34 system_message = SystemMessage(prompt) 35 36 res = self.llm_with_tools.invoke([system_message]) 37 38 logging.debug( 39 "[ReActNode] Executed LLM request: state = %s, response = %s", state, res 40 ) 41 return {"messages": [res]} 42 43 @abstractmethod 44 def get_system_prompt(self, state: StateT) -> str: 45 pass
The StateT type is generic, which means that any subclass can specify a custom state used in it, which makes this node very flexible. In the __call__ method I'm building a prompt that controls tool usage. Since the tools field is dynamic, I don't need to hardcode the tool usage guide inside my system prompt because I can generate it dynamically, based on the tools field state.
Subclasses of the ReActNode class should implement the get_system_prompt method which should return a node-specific prompt, but the subclass shouldn't care about common things implemented in the ReActNode class.
Core of the system - scan_node
Code available on GitHub.
The scan_node node is a subclass of the ReActNode class:
1from typing import override 2 3from langchain_core.language_models import LanguageModelInput 4from langchain_core.messages import AIMessage, BaseMessage, SystemMessage 5from langchain_core.runnables import Runnable 6 7from agent_core.node import ReActNode 8from scan_agent.state import ScanAgentState 9 10SCAN_BEHAVIOR_PROMPT = "Omitted for simplicity. Full prompt available on GitHub." 11 12 13class ScanNode(ReActNode[ScanAgentState]): 14 def __init__(self, llm_with_tools: Runnable[LanguageModelInput, BaseMessage]): 15 super().__init__(llm_with_tools=llm_with_tools) 16 17 @override 18 def get_system_prompt(self, state: ScanAgentState) -> str: 19 target = state.get("target", {}) 20 target_url = getattr(target, "url", "Unknown") if target else "Unknown" 21 target_description = ( 22 getattr(target, "description", "No description provided") 23 if target 24 else "No description provided" 25 ) 26 27 return SCAN_BEHAVIOR_PROMPT.format( 28 target_url=target_url, target_description=target_description 29 )
And it basically just provides scan-specific task prompt.
Control Edge - ToolRouterEdge
Code available on GitHub.
To control graph execution I used a dynamic routing edge:
1import logging 2from dataclasses import dataclass 3 4from langchain_core.messages import AIMessage 5 6from agent_core.state import ReActAgentState 7 8 9@dataclass 10class ToolRouterEdge[StateT: ReActAgentState]: 11 origin_node: str 12 end_node: str 13 tools_node: str 14 15 def __call__(self, state: StateT) -> str: 16 """Route based on tool calls and limits""" 17 last_message = state["messages"][-1] 18 usage = state["usage"] 19 tools_usage = state["tools_usage"] 20 tools = state["tools"] 21 tools_names = [t.name for t in tools.tools] 22 23 if usage.is_limit_reached(): 24 logging.info( 25 "Limit is reached, routing to end node: usage = %s, end_node = %s", 26 usage, 27 self.end_node, 28 ) 29 return self.end_node 30 31 if isinstance(last_message, AIMessage) and last_message.tool_calls: 32 logging.info("Routing to tools node: %s", self.tools_node) 33 return self.tools_node 34 35 if not tools_usage.is_limit_reached(tools_names): 36 logging.info( 37 "Limit is not reached: tools = %s, usage = %s, origin_node = %s", 38 tools_names, 39 tools_usage, 40 self.origin_node, 41 ) 42 return self.origin_node 43 44 logging.info( 45 "ToolRouterEdge: No tool calls found in the last message. " 46 "Usage limit reached. Routing to end node: %s. " 47 "Last message: %s", 48 self.end_node, 49 last_message, 50 ) 51 return self.end_node
This decides what node to call next based on the LLM decision and current tool usage.
Usually in the ReAct pattern, LLM decides what tools to call, but LLM is not a deterministic system and sometimes it can be lazy and use a tool only once or even never use it. We never know when LLM will decide to behave like this. To omit such cases, I decided to use LLM only as a "decision engine" but control tool calling from good old code with if-else statements:
LLM constantly calls tools
If tool usage exceeds the limit - stop using tools even if LLM decided to do so and go to the end_node
LLM doesn't call tools
If the LLM decides not to use any tool but tool usage didn't exceed the limit - restart previous node to force the LLM to decide what tool to use until tool usage exceeds the limit
Tools Results Processor - ProcessToolResultsNode
Code available on GitHub.
As mentioned above, I fought with the high LLM token usage problem and I introduced a special field in the state:
1class ReActAgentState(MessagesState): 2 results: Annotated[list[ToolResult], operator.add]
This contains tool result executions. But to populate this field I need to parse the LangGraph messages list in the ProcessToolResultsNode class:
1from langchain_core.messages import ( 2 AIMessage, 3 AnyMessage, 4 ToolMessage, 5) 6 7from agent_core.state import ReActAgentState, ToolResult 8import logging 9 10 11class ProcessToolResultsNode[StateT: ReActAgentState]: 12 def __call__(self, state: StateT) -> dict: 13 messages = state["messages"] 14 tools_usage = state["tools_usage"] 15 new_results = [] 16 17 results = state.get("results", []) 18 19 call_id_to_result = { 20 result.tool_call_id: result for result in results if result.tool_call_id 21 } 22 23 reversed_messages = list(reversed(messages)) 24 for msg in reversed_messages: 25 if isinstance(msg, ToolMessage): 26 if msg.tool_call_id not in call_id_to_result: 27 if msg.name is not None: 28 tools_usage.increment_usage(msg.name) 29 30 new_results.append( 31 ToolResult( 32 result=str(msg.content), 33 tool_name=msg.name, 34 tool_arguments=self._find_tool_call_args( 35 reversed_messages, msg.tool_call_id 36 ), 37 tool_call_id=msg.tool_call_id, 38 ) 39 ) 40 41 logging.debug( 42 "ProcessToolResultsNode: Processed tool results: %s", 43 new_results, 44 ) 45 return { 46 "results": list(reversed(new_results)), 47 "tools_calls": tools_usage, 48 } 49 50 def _find_tool_call_args( 51 self, messages: list[AnyMessage], tool_call_id: str 52 ) -> dict | None: 53 for msg in messages: 54 if isinstance(msg, AIMessage): 55 for tool_call in msg.tool_calls: 56 if tool_call.get("id") == tool_call_id: 57 return tool_call.get("args")
This basically associates current tool results with tool request messages and saves them in the graph state for next processing.
Summary Generation
Code available on GitHub.
After finishing scanning or reaching limits, we need to generate a summary that will be easy to consume by people or the next AI Agent in the chain:
1import json 2from langchain_core.language_models import BaseChatModel 3from langchain_core.messages import SystemMessage 4 5from scan_agent.state import ScanAgentState 6from scan_agent.state.scan_agent_state import ScanAgentSummary 7 8SUMMARY_BEHAVIOR_PROMPT = "Omitted for simplicity. Full prompt available on GitHub." 9 10class SummaryNode: 11 def __init__(self, llm: BaseChatModel): 12 self.structured_llm = llm.with_structured_output(ScanAgentSummary) 13 14 def __call__(self, state: ScanAgentState) -> dict: 15 target = state["target"] 16 17 system_prompt = SUMMARY_BEHAVIOR_PROMPT.format( 18 target_url=target.url, 19 target_description=target.description, 20 target_type=target.type, 21 tool_results=json.dumps([r.to_dict() for r in state.get("results", [])]), 22 ) 23 24 prompt_messages = [SystemMessage(content=system_prompt), state["messages"][-1]] 25 summary = self.structured_llm.invoke(prompt_messages) 26 27 return {"summary": summary} 28
Graph
Code available on GitHub.
To build a graph I used this code:
1from langchain_openai import ChatOpenAI 2from langgraph.checkpoint.memory import MemorySaver 3from langgraph.graph import END, START, StateGraph 4from langgraph.graph.state import CompiledStateGraph 5from langgraph.prebuilt import ToolNode 6 7from agent_core.edge import ToolRouterEdge 8from agent_core.node import ProcessToolResultsNode 9from agent_core.tool import ffuf_directory_scan, curl_tool 10from scan_agent.node import ScanNode 11from scan_agent.node.summary_node import SummaryNode 12from scan_agent.state import ScanAgentState 13 14 15def create_scan_graph() -> CompiledStateGraph: 16 llm = ChatOpenAI(model="gpt-4.1-2025-04-14", temperature=0.3) 17 tools = [ffuf_directory_scan, curl_tool] 18 llm_with_tools = llm.bind_tools(tools, parallel_tool_calls=True) 19 20 scan_node = ScanNode(llm_with_tools=llm_with_tools) 21 summary_node = SummaryNode(llm=llm) 22 process_tool_results_node = ProcessToolResultsNode[ScanAgentState]() 23 24 tools_router = ToolRouterEdge[ScanAgentState]( 25 origin_node="scan_node", 26 end_node="summary_node", 27 tools_node="scan_tools", 28 ) 29 30 builder = StateGraph(ScanAgentState) 31 32 builder.add_node("scan_node", scan_node) 33 builder.add_node("summary_node", summary_node) 34 builder.add_node("scan_tools", ToolNode(tools)) 35 builder.add_node("process_tool_results_node", process_tool_results_node) 36 37 builder.add_edge(START, "scan_node") 38 builder.add_edge("scan_tools", "process_tool_results_node") 39 builder.add_edge("process_tool_results_node", "scan_node") 40 builder.add_edge("summary_node", END) 41 42 builder.add_conditional_edges("scan_node", tools_router) 43 44 return builder.compile(checkpointer=MemorySaver())
Testing
To perform testing of my scan agent, I asked Claude Code to develop a vulnerable REST API with FastAPI and launched it locally. Code of that service is available here.
After execution of my agent on the specified target with this script:
1import uuid 2from datetime import timedelta 3 4from langchain_core.runnables.config import RunnableConfig 5 6from agent_core.graph import run_graph 7from agent_core.state import ReActUsage, Target, Tools, ToolsUsage 8from agent_core.tool import CURL_TOOL, FFUF_TOOL 9import logging 10 11logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s") 12 13state = { 14 "target": Target( 15 url="http://localhost:8000", description="Local REST API target", type="web" 16 ), 17 "usage": ReActUsage(limit=25), 18 "tools_usage": ToolsUsage( 19 limits={ 20 FFUF_TOOL.name: 2, 21 CURL_TOOL.name: 5, 22 } 23 ), 24 "tools": Tools(tools=[FFUF_TOOL, CURL_TOOL]), 25} 26thread_id = str(uuid.uuid4())[:8] 27config = RunnableConfig( 28 max_concurrency=10, 29 recursion_limit=25, 30 configurable={"thread_id": thread_id}, 31) 32 33print(f"🚀 Starting improved event processing with thread ID: {thread_id}") 34print("=" * 80) 35 36event = await run_graph(graph, state, config)
I got pretty solid results:
Loading...
My agent found critical vulnerabilities and that was just a scan agent, not an attack agent (about which I will explain in a next article). So I was very happy that this agent worked so well. LLMs have real power to make unexpected decisions which were literally impossible to code in the previous software era.
Summary
I built a simple agent to perform cybersecurity scanning and it worked amazingly well. Modern LLMs provide great power for software engineers to build really powerful systems that were just impossible to build before LLMs. I'm excited to build more agents and solve real world problems.
Main insights for ReAct agent development:
- To minimize LLM token usage, you need to save tool output in the graph state instead of simply using a list of messages.
- To guarantee sufficient tool usage, you need to control it from the source code instead of relying on the LLM decision.
In the next article I will explain how to combine multiple AI Agents to perform complete cybersecurity assessment for a system with LangGraph.
Subscribe to my Substack to not miss my new articles 😊
📧 Stay Updated
Get weekly insights on backend development, architecture patterns, and startup building directly in your inbox.
Free • No spam • Unsubscribe anytime
Share this article
Related articles
Spec-Driven Development: How AI Coding Moves Beyond Vibe Coding
Spec-driven development turns AI coding from constant vibe coding into a structured workflow with specs, plans, tasks, and autonomous implementation.
LLM Prompt Evaluation with Python: A Practical Guide to Automated Testing
Learn how to evaluate LLM prompt quality using Python with practical examples from an open-source AI product research project. Discover automated testing techniques to ensure consistent, high-quality outputs from your AI applications while minimizing costs.
