LLM Prompt Evaluation with Python: A Practical Guide to Automated Testing
Introduction
During the last couple of months, I haven't written new blog posts due to a project I was working on. But I decided to return to writing a blog because I love it. And today I will explain how to evaluate LLM prompt quality with Python using the example of my Open Source project - ai-product-research.
Problem Statement
Loading...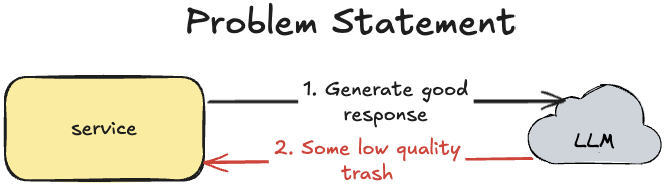
During development of AI-powered applications/features, it's very easy to define a prompt which should do something, for example generate a summary of a complex data structure or provide a product analysis. But when you are defining a prompt like:
1You are a product manager who specializes in filtering AI-powered software products. 2 3Your task: Analyze the provided product and decide if it matches ALL three requirements. 4 5REQUIREMENTS (ALL must be met): 6...
You never know if it really works. Because sometimes LLM for some input will provide a good response, but for different input it will provide low quality responses. And this is a critical problem because quality of LLM applications is not guaranteed.
Proposed solution
To solve a quality problem with LLM we have two options:
- Manual testing
- Automatic testing
Option 1: Manual Testing
In this option we need to allocate human resources to do testing for all possible inputs for LLM and make a decision if a new version of the LLM prompt is good or not. This option is not so good because it's expensive, error prone, and very long to get a result of prompt changes.
I don't recommend using manual testing during AI application development.
Option 2: Automatic Testing
In this option we need to write automatic tests which will take all test cases and execute LLM prompt on them. After that we need to make a decision if the prompt is good enough or not.
And these automatic tests are different from regular automatic tests used in software development previously because, due to a non-deterministic LLM nature, we can't write deterministic tests which will guarantee that output will be 100% equal to the expected one.
That's why automatic tests for LLM prompts should be developed in another way:
Loading...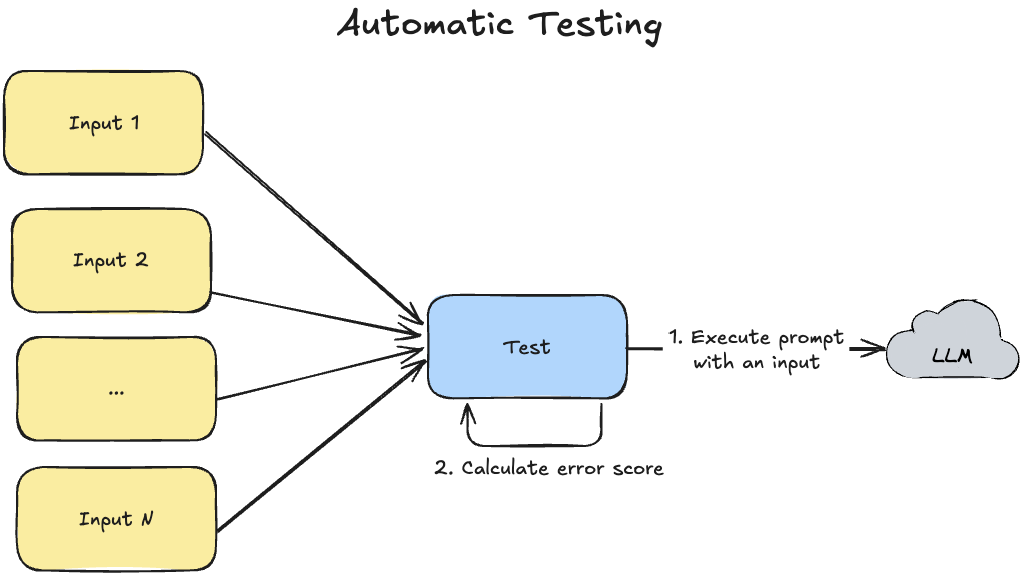
- Execute prompt with all inputs one by one
- Calculate error score for LLM outputs
- Calculate average error score for all inputs and compare it with a threshold
The critical point is that we are not comparing outputs from the tested code (prompt) with expected ones as in usual tests. Instead, we are calculating an error score and comparing it with a threshold (for example, 0.9 which means that output should be correct in 90% of cases). That's why these kinds of tests are named as prompt evaluation and not regular tests.
I do recommend using this technique during development of AI applications. During my work with AI applications, it has proven that by evaluating prompts I can make AI applications cheaper by using smaller models and still maintain high quality.
Example of Prompt Evaluation
I have built an application which analyzes published Product Hunt products - ai-product-research. It literally automated my own product analysis workflow which I did manually:
Loading...
Work is still in progress, but generally AI automation works in this way:
Loading...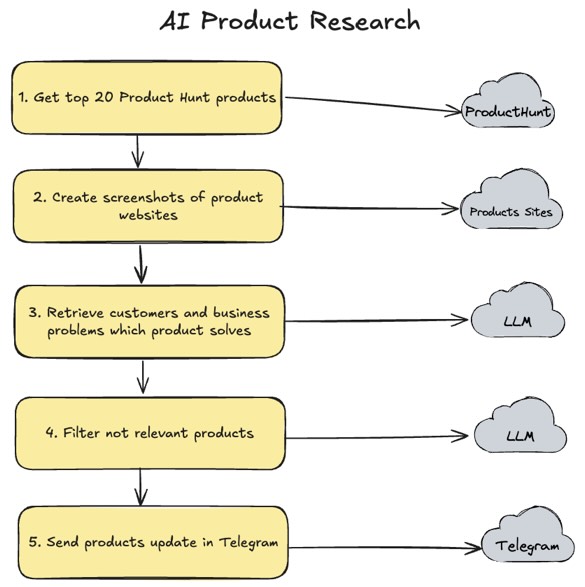
So this is a simple AI automation for newly released products. On the "3. Retrieve customers and business problems which product solves" step, I used OpenAI ChatGPT-4o Mini model to analyze screenshots and retrieve information. I used screenshot analysis instead of raw HTML analysis due to the fact that most sites are React based and HTML may not contain all information - that's why I did smarter scraping.
But anyway the problem was the same: retrieve information with LLM in a cheap and high-quality way.
Prompt Evaluation: Retrieve customers and business problems
The nature of customers and business problem description is non-deterministic, so to evaluate the prompt it's not enough to define expected results and calculate error score. Instead, we need to analyze text provided by LLM in the output. And to do it I decided to use another LLM - LLM judge. So evaluation works in this way:
- Execute LLM prompt with provided input
- Evaluate LLM output with LLM judge and provide success score
- Calculate average success score for all inputs
- Compare average score with a threshold. If average score is equal to or bigger than a threshold - test passed, otherwise failed
Code is available on GitHub: test_problem_retriever_agent.py.
Prompt Evaluation: Filter not relevant products
I don't want to receive updates for all products in my Telegram channel, so I decided to add filtering by LLM to send only those products which are related to the AI field. And to minimize costs for filtering, I use GPT-4o Nano model which is cheap but not very smart. That's why prompt evaluation is super critical here.
The approach of prompt evaluation was the same as in the previous example, with one exception: my original prompt was returning a reason why the product was filtered. This reason was used in the prompt optimization with Claude Code, which allowed me to automatically develop a prompt by just writing evaluation test and original prompt skeleton. After that I told Claude Code to run evaluation test and optimize LLM prompt until the threshold passed.
Code is available on GitHub: test_product_filter_agent.py.
Conclusions
In this article I explained how to use the prompt evaluation technique to ensure that AI applications will provide stable high quality. I do recommend always writing prompt evaluations for all AI applications and not developing a black box without a guarantee that it will work.
📧 Stay Updated
Get weekly insights on backend development, architecture patterns, and startup building directly in your inbox.
Free • No spam • Unsubscribe anytime
Share this article
Related articles
Spec-Driven Development: How AI Coding Moves Beyond Vibe Coding
Spec-driven development turns AI coding from constant vibe coding into a structured workflow with specs, plans, tasks, and autonomous implementation.
How I Built an AI-Powered YouTube Shorts Generator: From Long Videos to Viral Content
Complete technical guide to building an automated YouTube Shorts creator using Python, OpenAI Whisper, GPT-4, and ffmpeg. Includes full source code, architecture patterns, and performance optimizations for content creators and developers.
