Designing AI Applications: Principles from Distributed Systems Applicable in a New AI World

Introduction
For more than a year, I've been exploring AI Engineering by observing numerous new startups leveraging AI and launching my own products. AI is a super hot topic, and when you first try to build an AI tool or read about AI applications, it seems like a magical world where completely new principles are applied. But the key thing I learned during this period is that building AI applications is a process that's not too different from building distributed systems where reliability is a mandatory requirement.
In this article, I will explain how to build AI applications by applying distributed systems principles to make applications reliable and scalable.
Main Problem
Loading...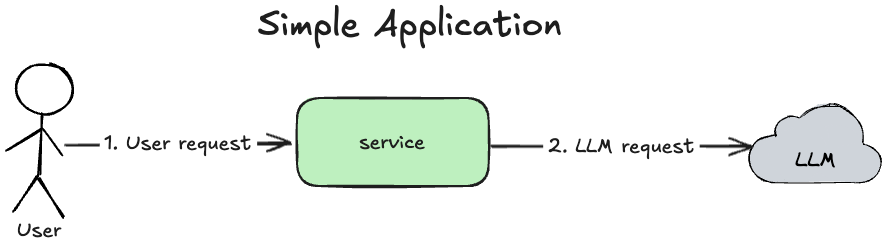
Let's consider an example of the simple application:
- User sends a request to a service
- Service sends a request to LLM
- LLM returns a response
- Service returns a response to user
The main problem is that LLMs don't respond reliably, and too often LLM providers return 429 Too Many Requests errors. In this case, users will be unhappy but can retry a request themselves (or leave the app and never use it again).
But the situation gets worse when we have async user request processing, where the service accepts a user request and starts a batch job that needs to perform N communications with the LLM.
Loading...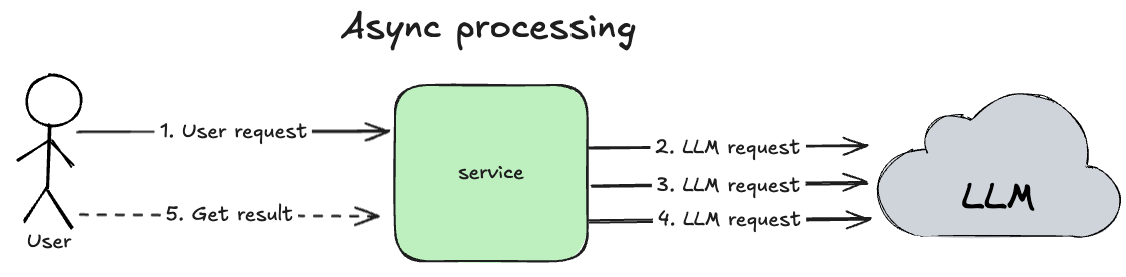
What if on the 3rd LLM request, the LLM returns a 429 Too Many Requests error and our batch job fails?
Loading...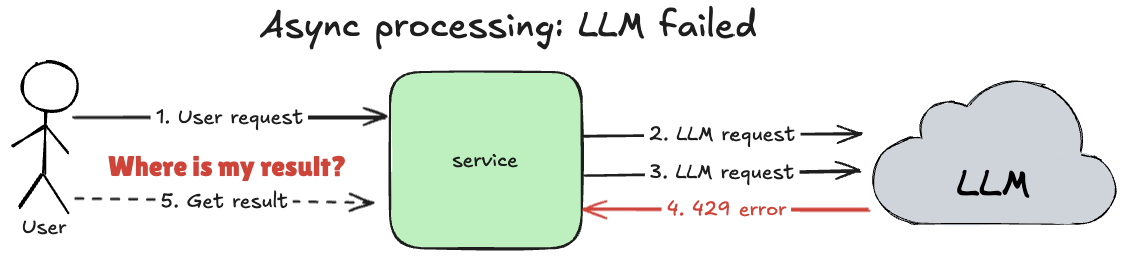
In the end, when users check the results, they'll receive an empty response because the LLM failed to process the job, which will result in losing this user and, at scale, losing many such users.
To deal with this situation, there is a solution, and it's not OpenRouter 😉.
Solution
The problem described above is a classic vendor dependency problem in software engineering, where the vendor API is not reliable and you can't go down when the vendor is unable to handle your request. To solve this, we need to use:
- Retries - the most genius things in the world are simple.
- Timeout between retries - because we don't want to DDoS the vendor and need to allow them to heal their systems in case of outages.
- Durability - a guarantee that if we accepted a user request, we will handle it with 100% guarantee.
There are two options for how these properties can be implemented.
Option 1: In-Memory Retries
The most obvious and simple solution is to add a for-loop and retry if an exception happens:
1async def send_request_with_retries(): 2 err = None 3 for i in range(0, 10): # 1. Retries 10 times 4 if i > 0: 5 await asyncio.sleep(random.uniform(0.05, 0.2)) # 2. Randomly sleeps 6 try: 7 return do_request() 8 except Exception as e: 9 err = e 10 raise RuntimeError(f"unable to process a request: {err}") # 3. Throws error
This code works like this:
- Retries a request at most 10 times
- Randomly sleeps between retries from
50 msto200 msto not overload the LLM API. We can't use a fixed sleep timeout here because it would still work as a DDoS. - If we reach the retry limit, throw an error
The code is simple, but it doesn't solve the last property: Durability. If our service fails in the middle of the for loop, we'll forget about this request and never retry it again. This is not an issue in Option 2.
Option 2: Transactional Outbox Pattern
Instead of running a simple retry loop, we can use the Transactional Outbox Pattern.
Loading...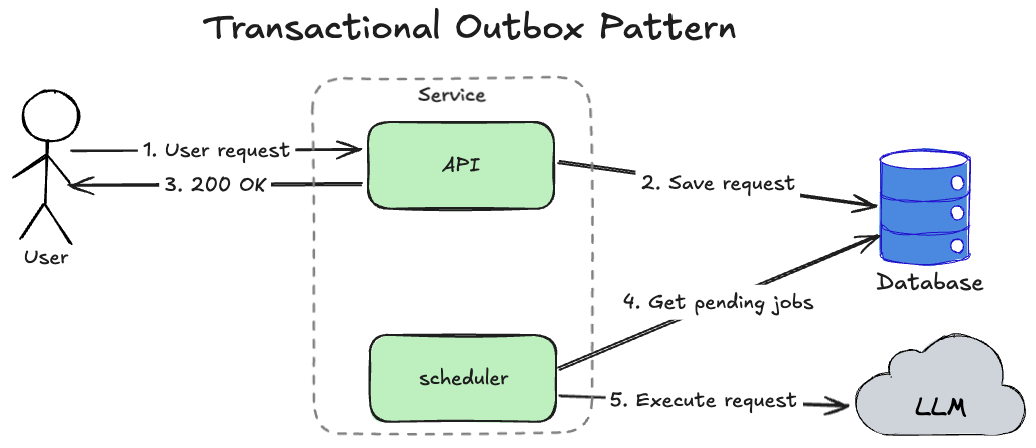
- User sends a request to our service.
- Service saves the request to a database.
- Service responds
200 OKto the user. - The
schedulermodule in the service checks every1 secondfor pending jobs in the database. - The
schedulermodule executes the LLM request if a pending job is in the database, and if LLM execution is successful, it saves the execution result in the database and marks the pending job as done.
This pattern ensures that if the service accepts a user request, it will provide a 100% guarantee that the request will be handled (or near 100% because limits are applicable here as well).
If we have a reliable mechanism to call LLMs, it allows us not only to make the application reliable but also to reduce LLM costs. Instead of using expensive LLMs like Anthropic or OpenAI, we can use cheap models like DeepSeek and significantly reduce the costs of running the application.
Fun fact: I spent $20 during development of reddit-agent just for running local tests. But after implementing the Transactional Outbox pattern, I completely migrated from OpenAI API to DeepSeek, and right now reddit-agent costs me $0 because the LLM is not reliable but free, and the reliable pattern makes it reliable.
Internally, the scheduler module will use retry logic from Option 1 but also adds a persistence layer to ensure that the service will handle user requests.
During the rest of this article, I will explain how to adopt this Transactional Outbox pattern using the example of my application reddit-agent, which I built specifically for this article. The source code is available on GitHub.
Example: reddit-agent
I built an AI Agent that researches Reddit for predefined topics. It is available at https://insights.vitaliihonchar.com/.
The design is shown in this diagram:
Loading...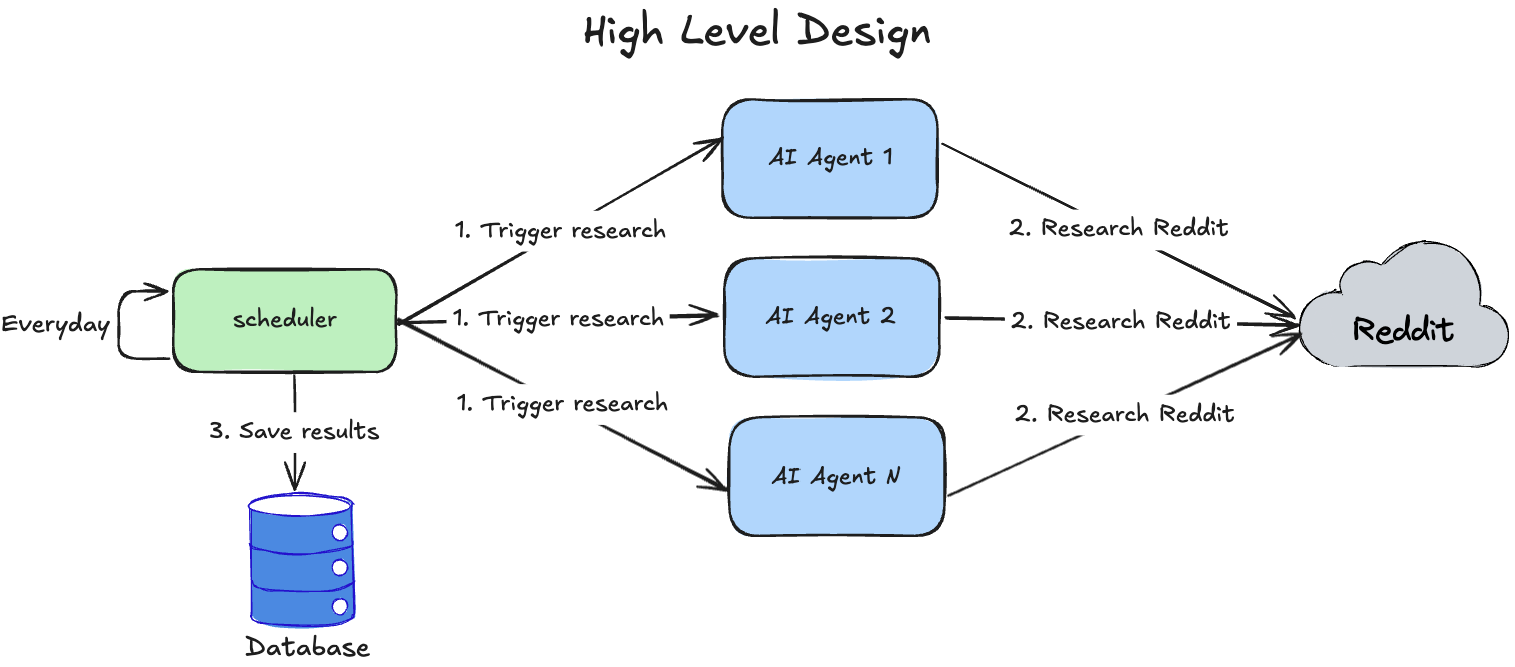
Every day, the scheduler executes a batch of AI Agents that analyze Reddit and try to retrieve information specified in prompts.
Each agent was implemented with the ReAct pattern:
Loading...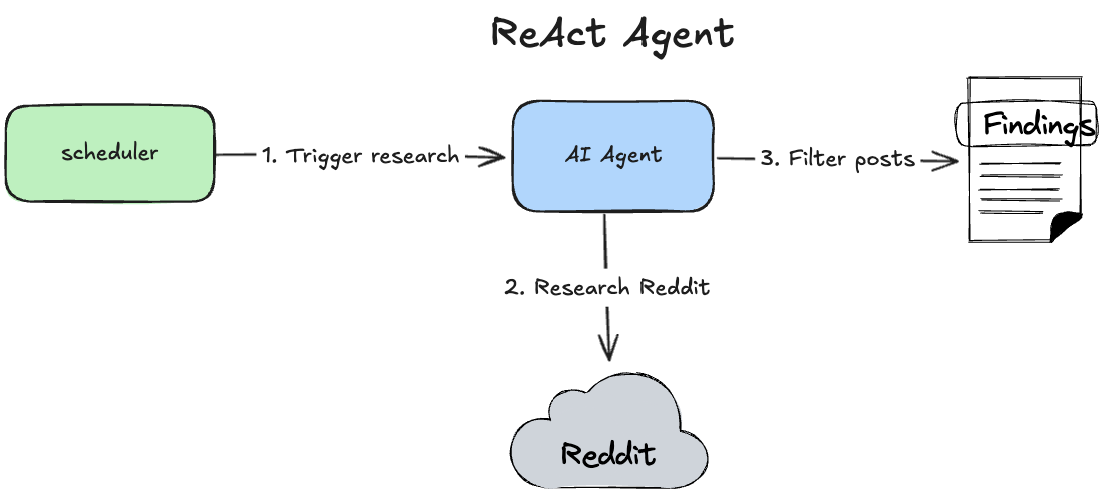
The ReAct pattern is a perfect choice here because it allows LLM creativity to find the right posts and analyze them.
Finally, users can read findings on the insights page:
Loading...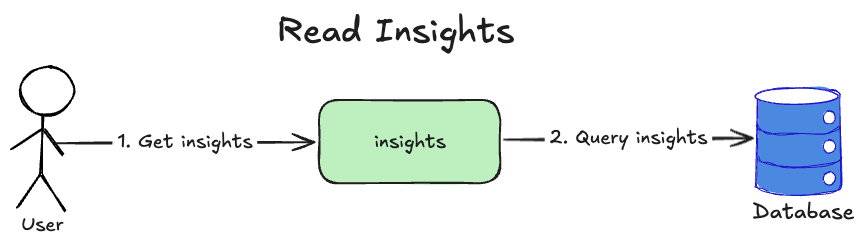
Implementation: reddit-agent
It's all clear about the high-level design, but the details are where things get complex. To implement my service, I want to make it scalable to have an example of an AI application that is reliable and scalable. So let's look at its architecture:
Loading...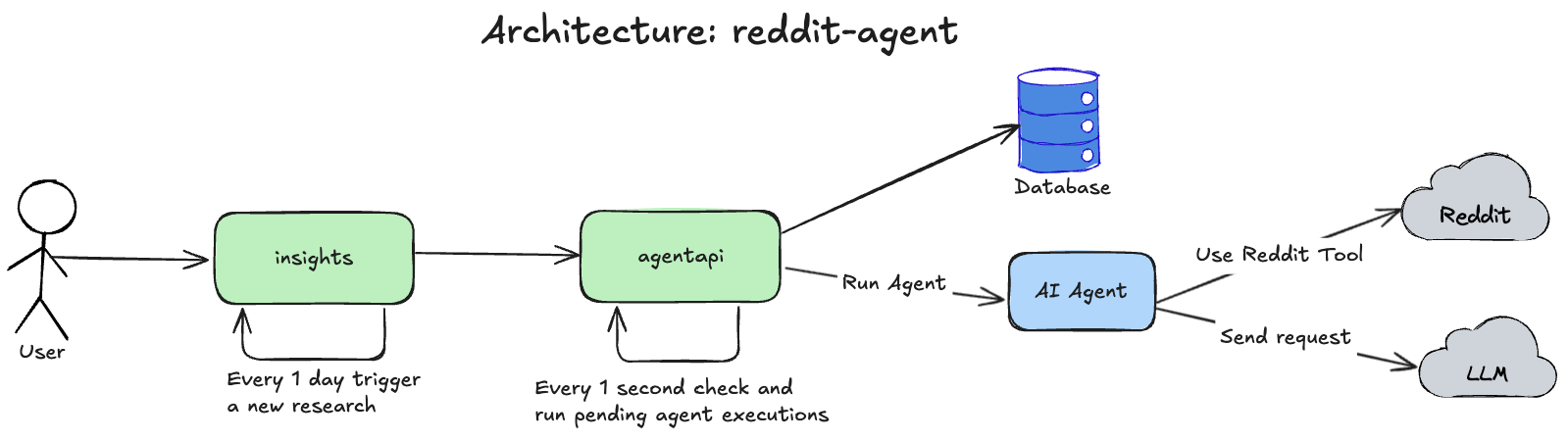
I introduced 2 services:
insights- web UI that is responsible for serving user requests and showing a page with insights, available at insights.vitaliihonchar.comagentapi- a generic platform to run LangGraph agents, which currently contains only one AI Agent - Reddit Search Agent. I have some plans for AI Agent experiments, which is why I developed a generic platform to have flexibility in the future.
This agentapi implements the Transactional Outbox pattern by allowing any agent to be executed via API:
Loading...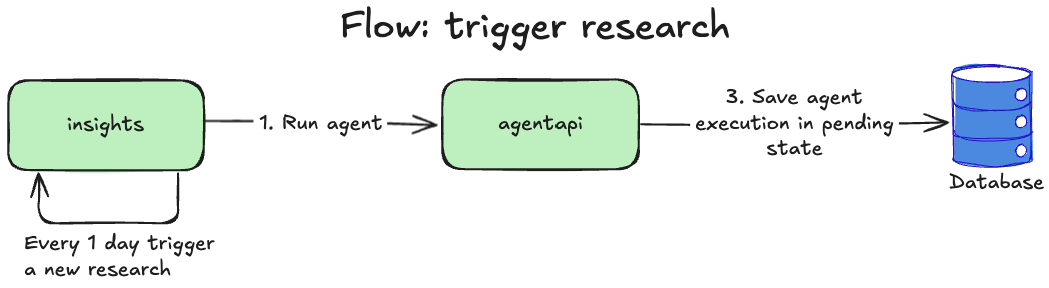
When insights executes an agent, agentapi simply saves AgentExecution in the pending state in the database.
And a scheduler inside agentapi checks every 1 second for pending executions in the database:
Loading...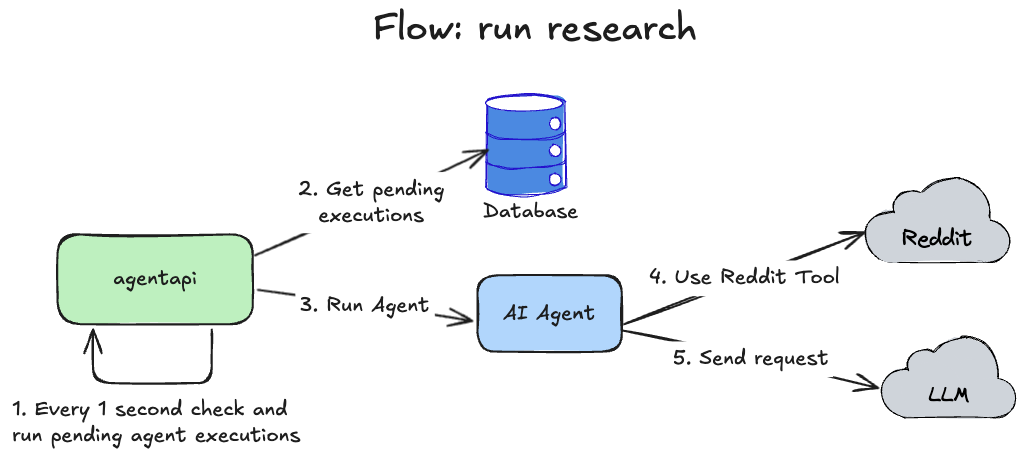
So if the LLM fails at any step of execution, my scheduler inside agentapi will restart the agent.
Transactional Outbox Pattern Implementation
The most interesting part is how to query pending agent executions, because it's a common performance bottleneck in a wrongly implemented Transactional Outbox pattern that I've observed in different companies during my career.
This is a good topic for another article, but in short: do not use pessimistic locks to get pending jobs from the database; instead use optimistic locks. A detailed implementation is on GitHub:
- Find pending agent executions - find agent executions that match criteria. Always specify a time threshold and do not query the most recent ones, because there's a possibility that another node is concurrently handling the same agent executions, and we don't want to handle them twice.
- Optimistically acquire a lock for an agent execution - just compare the state in the database with the in-memory state, and if it matches, update the record in the database while incrementing a counter.
A - atomicityensures that one of the concurrent updates will succeed and another will fail, returning 0 affected rows in the result. For all0s, we say that we can't acquire a lock and just skip thisagent executionfor now.
Lock looks like this in SQL (but need to commit transaction as fast as possible to minimize SQL contention):
1UPDATE agent_execution 2SET state = 'processing', 3 executions = executions + 1 4WHERE id = ? 5 AND state = 'pending' 6 AND executions = ?
So this approach is super efficient for Postgres, MySQL, CockroachDB, and MongoDB databases (I've implemented it for all of them in different projects at different companies during the last 5 years) and allows us to scale our services without a database bottleneck.
As a result, each scheduler is not guaranteed to execute the same number of jobs as received in the initial find pending jobs query, but that's OK because another scheduler concurrently executes the missed jobs, and it works fine for a distributed system.
Benefits of Transactional Outbox Pattern
This pattern improves the reliability and scalability of applications, which allows us to:
- Improve user experience by ensuring that almost all user requests will be processed.
- Use cheaper LLMs or even self-host Open Source LLMs with less strict uptime guarantees, which will significantly reduce infrastructure bills. (This is what I did by moving from OpenAI to DeepSeek, as I mentioned above).
So again, no OpenRouter needed here to improve AI application reliability - just old software engineering practices proven over time.
Scalability
Let's consider the second important topic of today's problem - scalability. We've applied the pattern described above, and our application reliably handles user requests, but how do we scale it? If the Transactional Outbox Pattern was implemented correctly, it's trivial - just deploy more nodes.
Also, with the Transactional Outbox Pattern, we don't need to fear scaling nodes as we did previously due to reaching request limits in LLMs, because even if we receive errors, we'll retry them.
So with the described approach, it's very easy to scale AI applications.
Conclusions
In this article, I explained why we need to use the Transactional Outbox Pattern for AI applications. This is my first article in a series on applying distributed systems knowledge in the new AI world. Key outcomes:
- To achieve AI application reliability, you need to use the Transactional Outbox Pattern.
- To implement the Transactional Outbox Pattern, you need to use optimistic locks, not distributed locks or pessimistic locks.
- Do not rely on external services like OpenRouter for reliability; instead, use proven software engineering practices.
Subscribe to my Substack to not miss my next articles, in which I'm planning to focus on:
- Observability in AI applications
- Infrastructure for AI applications
- Development best practices for AI applications development
📧 Stay Updated
Get weekly insights on backend development, architecture patterns, and startup building directly in your inbox.
Free • No spam • Unsubscribe anytime
Share this article
Related articles
Spec-Driven Development: How AI Coding Moves Beyond Vibe Coding
Spec-driven development turns AI coding from constant vibe coding into a structured workflow with specs, plans, tasks, and autonomous implementation.
LLM Prompt Evaluation with Python: A Practical Guide to Automated Testing
Learn how to evaluate LLM prompt quality using Python with practical examples from an open-source AI product research project. Discover automated testing techniques to ensure consistent, high-quality outputs from your AI applications while minimizing costs.
