Flow-Run System Design: Building an LLM Orchestration Platform
Introduction
In the last blog post I scoped the flow-run project requirements. It answered the question "what?". But before jumping into development, I need to answer the "how?" question and create the system design.
Check my previous post: flow-run: LLM Orchestration, Prompt Testing & Cost Monitoring
The system design for flow-run is split into three parts:
flow-runservice design- Prompts DSL design
- API design
During the design process for flow-run, I recorded live-design YouTube videos:
High Level Design
Loading...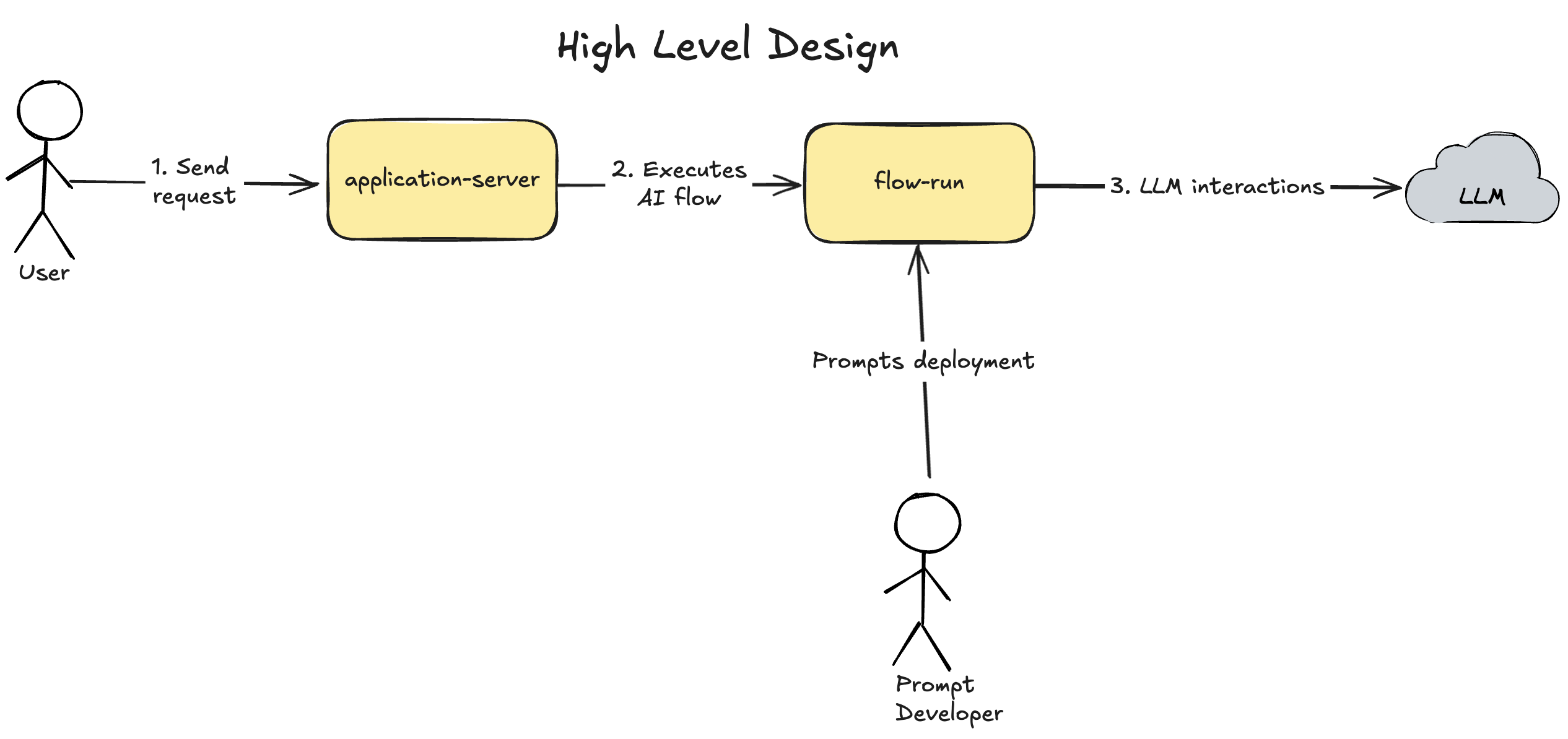
During the development phase, developers will develop and deploy prompts to the flow-run service.
In the production:
- User sends a request to
application-server application-serverexecutes the specified flow inflow-runflow-runcommunicates with LLM and executes the flow itselfapplication-servereventually gets the execution result fromflow-run
Prompts will be deployed as YAML files and described in the "Prompts DSL design" section.
flow-run service design
Task
Task is the atomic unit of work which flow-run can execute.
Loading...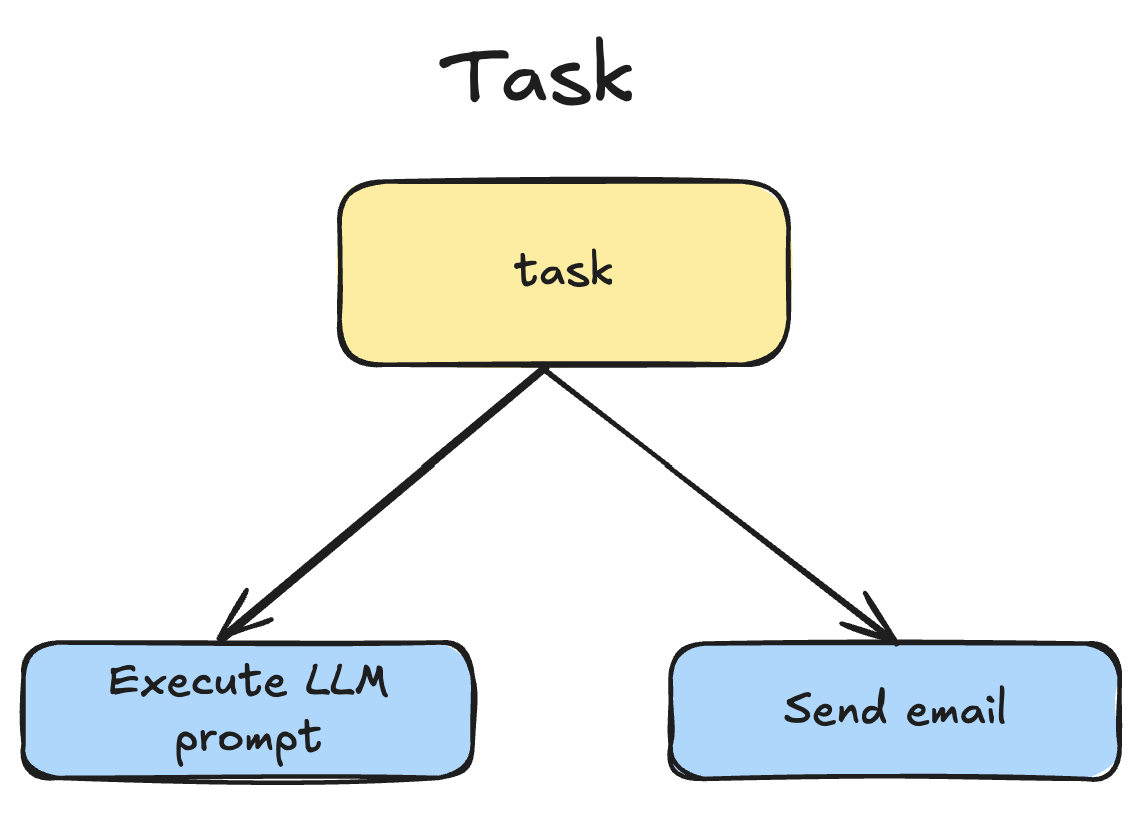
It can be:
- Execute LLM prompt task
- Send email task
- etc.
Task Flow
Task flow is a graph of connected tasks that executes tasks based on the connections between them. It can execute tasks sequentially or in parallel depending on how the graph was created. Parallel task execution can be achieved by using BFS (breadth-first search) to traverse a graph.
Loading...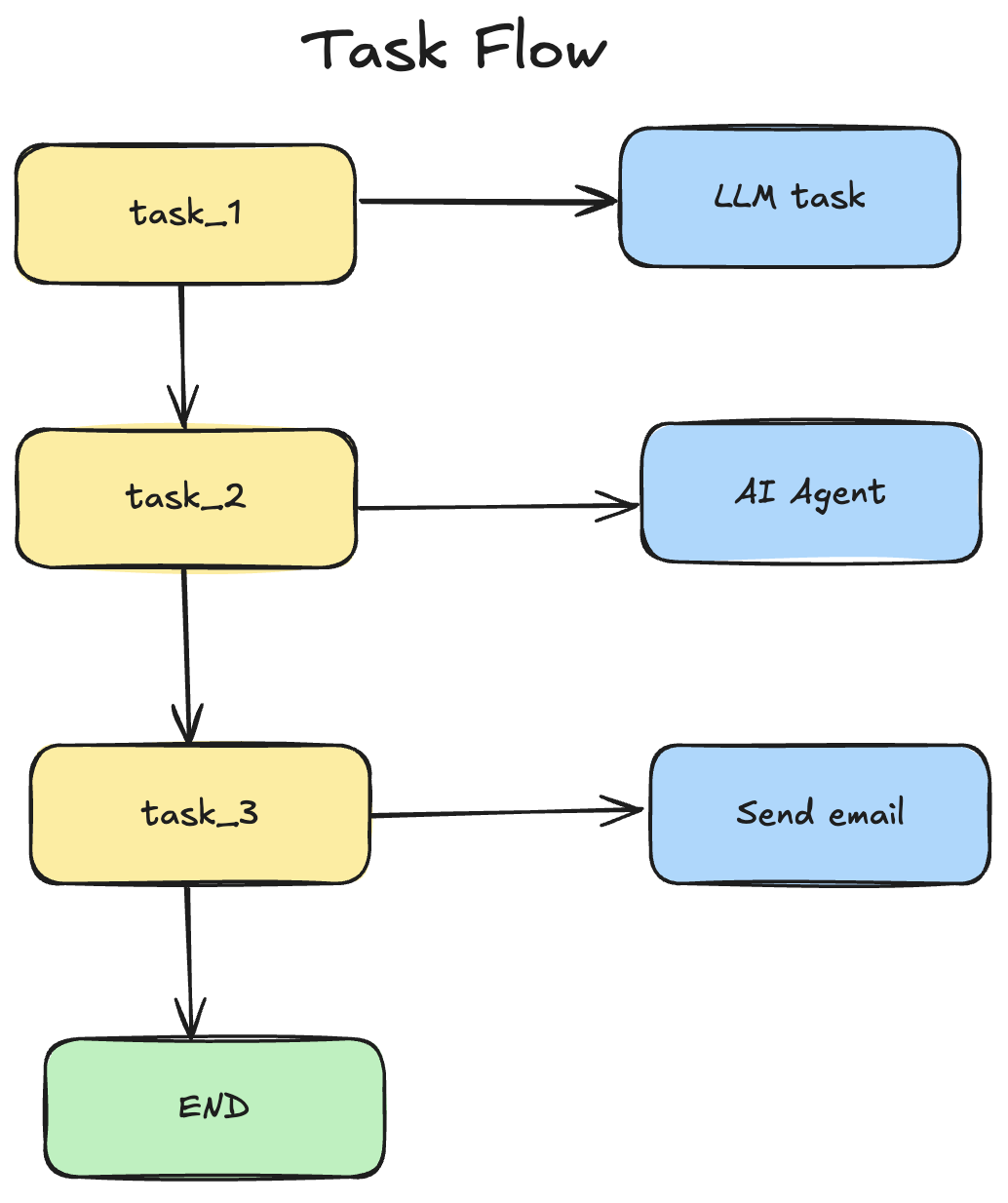
Task is a vertex in the graph and can be anything from an LLM execution task to sending an email.
Data Schema
Loading...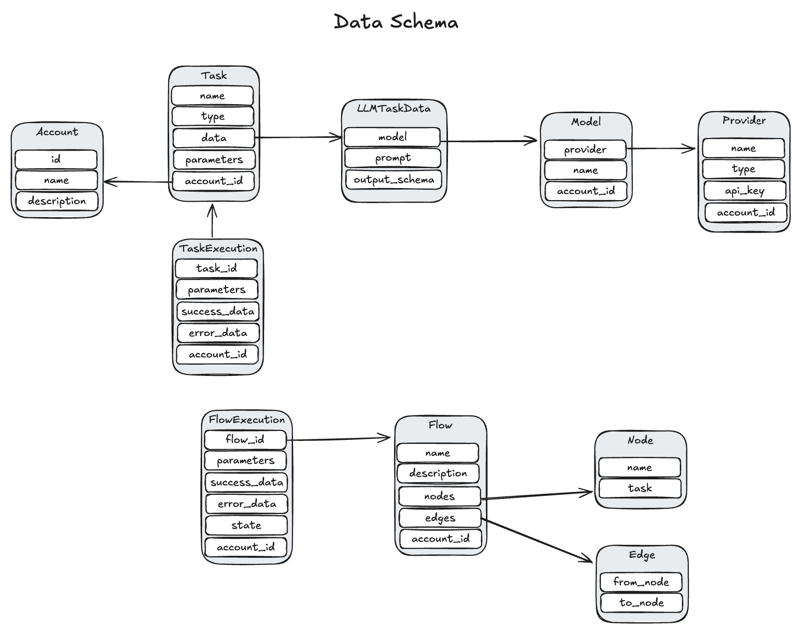
flow-run includes these entities:
Account- user account used to implement a multi-tenant system in theflow-runservice and allow isolation of different teams from each other inside one company or build SaaS with multiple users without allowing them to access the same API keys in a provider or the same flows/tasksProvider- LLM provider which contains API keyModel- LLM model used by a task to perform LLM actions, for examplegpt-4.1Task- task which contains information about its parameters and configuration in thedatafieldLLMTaskData- task data specific to theTaskwith thellmtype. Contains configuration for LLM taskTaskExecution- runtime data for executed task. Used to track task executions and retriesFlow- task flow which is a graph and contains nodes and edges that connect tasksFlowExecution- runtime data for executed flow. Used to track flow executions and retriesNode- graph node which is saved in the embedded fieldnodesand contains the name of a task that should be executed when the node is runningEdge- graph edge that connects nodes
This data schema design is flexible and allows flow-run to:
- Support multi-tenancy
- Reliably run tasks
- Reliably run flows
Execution Engine
Since Flow contains nodes inside it which refer to tasks, we have an execution engine that controls executions of:
- Flow
- Task
separately, which simplifies implementation by using the Single Responsibility principle because the execution engine in each period of time should focus only on one entity to execute.
Task Execution
Loading...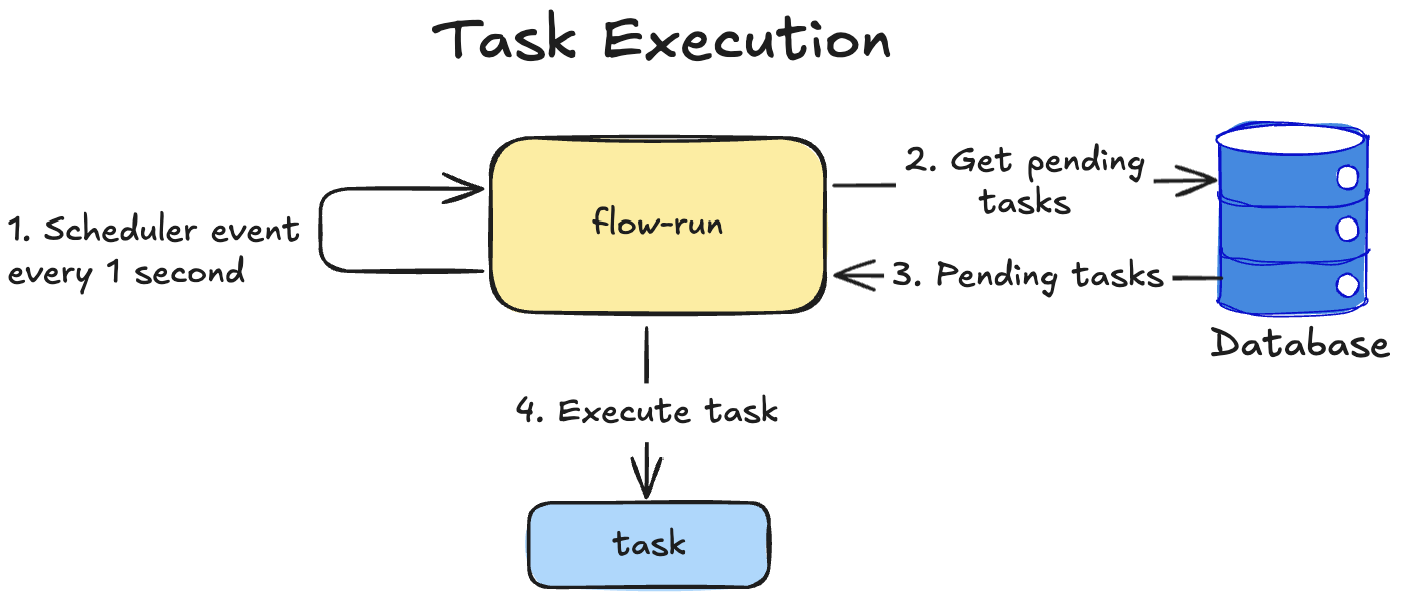
- Scheduler triggers an event every 1 second
flow-rungets pending tasks from the databaseDatabasereturns pending tasks or an empty response- If some pending task is present,
flow-runexecutes it and if execution is successful, marks it as a successful execution inDatabase
Pending task is the
TaskExecutionentity withstatus = pending.
Task Flow Execution
Loading...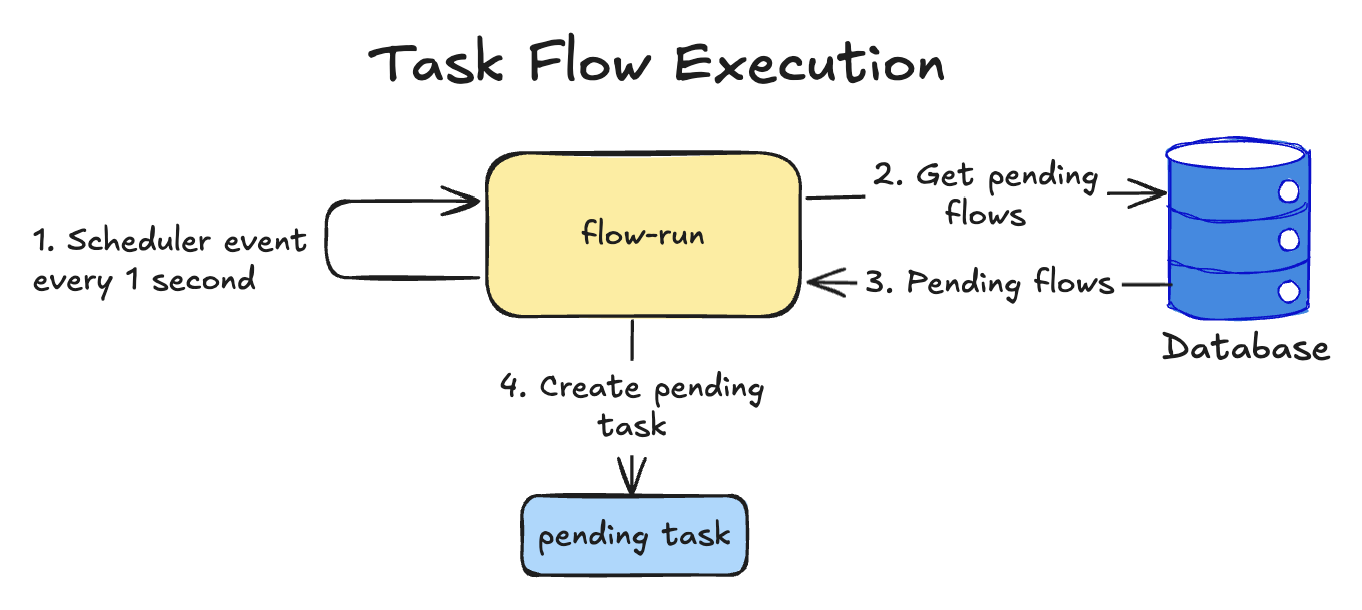
- Scheduler triggers an event every 1 second
flow-rungets pending flows from the databaseDatabasereturns pending flows or an empty response- If some pending flow is present,
flow-runruns BFS in the graph and after getting a list of nodes to execute, creates pending tasks for each node. If theENDnode was reached, thenflow-runmarksFlowExecutionas successful
Pending flow is the
FlowExecutionentity withstatus = pending.
Prompts DSL design
Prompt Developer will use YAML as DSL language to describe tasks and flows. YAML was chosen here because it's the most known file format for IaC tools and the simplest to implement for MVP.
Loading...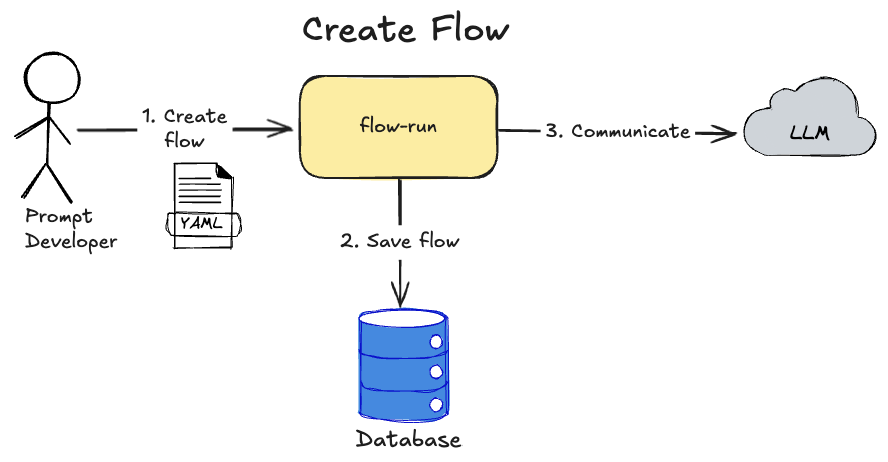
So to create Flow with tasks, Prompt Developer will upload a YAML file with entity definitions to the flow-run service.
YAML DSL language should support all flow-run entities to be considered an IaC tool, so let's see DSL for each entity.
Provider
1providers: 2 - name: "DevOps LLM Provider 2" 3 type: openai 4 api_key: 267c8baa-7beb-11f0-8091-5ee52574761b 5 - name: "Developers LLM Provider" 6 type: openai 7 api_key: 267c8baa-7beb-11f0-8091-5ee52574761b
Model
1models: 2 - name: "gpt-4.1" 3 provider: "DevOps LLM Provider 2" 4 - name: "gpt-4.1" 5 provider: "Developers LLM Provider"
Task
1models: 2 - name: "Analyze Terraform PR" 3 type: "llm_task" 4 data: 5 model: "gpt-4.1" 6 prompt: "Analyze this PR" 7 output_schema: 8 change_requests: 9 type: array 10 description: "Array of change requests. If no change requests, this should be empty." 11 items: 12 type: string 13 recommendations: 14 type: array 15 description: "Array of recommendations for improving the PR" 16 items: 17 type: string 18 review_status: 19 type: string 20 enum: ["APPROVE", "CHANGE_REQUEST", "COMMENT"] 21 description: "Overall review status for the PR" 22 parameters: 23 url: 24 type: string 25 description: "URL to GitHub PR" 26 jira_task: 27 type: string 28 description: "URL to Jira task with requirements"
Flow
1flows: 2 - name: "DevOps analysis" 3 description: "Code analysis" 4 nodes: 5 - name: "Start Node" 6 task: "Analyze Terraform PR" 7 - name: "Second Node" 8 task: "Second Task" 9 edges: 10 - from: "Start Node" 11 to: "Second Node"
With these DSL entities, the whole infrastructure for prompts can be created from code.
API Design
Main principles of API design for flow-run:
- For creation operations,
idshould be populated by the client during creation of a provider to perform deduplication and not allow creation of two identical providers due to network lag or client retry /v1prefix (API versioning) should be used in each endpoint to simplify system maintainability in the future and allow publishing a new version of an endpoint without breaking the old one
Account
POST /v1/account
Description: Creates account
Request body:
1{ 2 "id": <uuid>, 3 "name": "DevOps Account", 4 "description": "DevOps team" 5}
Response body:
1{ 2 "id": <uuid> 3}
GET /v1/account/:id
Description: Reads account
Response body:
1{ 2 "id": <uuid>, 3 "name": "DevOps Account", 4 "description": "DevOps team" 5}
PUT /v1/account/:id
Description: Updates account
Request body:
1{ 2 "id": <uuid>, 3 "name": "DevOps Account", 4 "description": "DevOps team" 5}
Response body:
1{ 2 "id": <uuid> 3}
DELETE /v1/account/:id
Description: Deletes account
Provider
POST /v1/provider
Description: Creates provider
Request body:
1{ 2 "id": <uuid>, 3 "name": "DevOps LLM provider", 4 "type": "openai", 5 "api_key": <api_key>, 6 "account_id": <account_id> 7}
Response body:
1{ 2 "id": <uuid> 3}
GET /v1/provider/:id
Description: Reads provider
Response body:
1{ 2 "id": <uuid>, 3 "name": "DevOps LLM provider", 4 "type": "openai", 5 "api_key": <api_key>, 6 "account_id": <account_id> 7}
PUT /v1/provider/:id
Description: Updates provider
Request body:
1{ 2 "id": <uuid>, 3 "name": "DevOps LLM provider", 4 "type": "openai", 5 "api_key": <api_key>, 6 "account_id": <account_id> 7}
Response body:
1{ 2 "id": <uuid> 3}
DELETE /v1/provider/:id
Description: Deletes provider
Model
POST /v1/model
Description: Creates model
Request body:
1{ 2 "id": <uuid>, 3 "name": "gpt-4.1", 4 "provider_id": <provider_id>, 5 "account_id": <account_id> 6}
Response body:
1{ 2 "id": <uuid> 3}
GET /v1/model/:id
Description: Reads model
Response body:
1{ 2 "id": <uuid>, 3 "name": "gpt-4.1", 4 "provider_id": <provider_id>, 5 "account_id": <account_id> 6}
PUT /v1/model/:id
Description: Updates model
Request body:
1{ 2 "id": <uuid>, 3 "name": "gpt-4.1", 4 "provider_id": <provider_id>, 5 "account_id": <account_id> 6}
Response body:
1{ 2 "id": <uuid> 3}
DELETE /v1/model/:id
Description: Deletes model
Task
POST /v1/task
Description: Creates task
Request body:
1{ 2 "id": <uuid>, 3 "name": "Analyze Terraform PR", 4 "type": "llm_task", 5 "data": <task_data>, 6 "parameters": <task_parameters>, 7 "account_id": <account_id> 8}
Response body:
1{ 2 "id": <uuid> 3}
GET /v1/task/:id
Description: Reads task
Response body:
1{ 2 "id": <uuid>, 3 "name": "Analyze Terraform PR", 4 "type": "llm_task", 5 "data": <task_data>, 6 "parameters": <task_parameters>, 7 "account_id": <account_id> 8}
PUT /v1/task/:id
Description: Updates task
Request body:
1{ 2 "id": <uuid>, 3 "name": "Analyze Terraform PR", 4 "type": "llm_task", 5 "data": <task_data>, 6 "parameters": <task_parameters>, 7 "account_id": <account_id> 8}
Response body:
1{ 2 "id": <uuid> 3}
DELETE /v1/task/:id
Description: Deletes task
POST /v1/task/:id/execute
Description: Executes task
Request body:
1{ 2 <task_parameters> 3}
Response body:
1{ 2 "id": <uuid> 3}
Flow
POST /v1/flow
Description: Creates flow
Request body:
1{ 2 "id": <uuid>, 3 "name": "DevOps analysis", 4 "description": "Code analysis", 5 "nodes": <nodes>, 6 "edges": <edges>, 7 "account_id": <account_id> 8}
Response body:
1{ 2 "id": <uuid> 3}
GET /v1/flow/:id
Description: Reads flow
Response body:
1{ 2 "id": <uuid>, 3 "name": "DevOps analysis", 4 "description": "Code analysis", 5 "nodes": <nodes>, 6 "edges": <edges>, 7 "account_id": <account_id> 8}
PUT /v1/flow/:id
Description: Updates flow
Request body:
1{ 2 "id": <uuid>, 3 "name": "DevOps analysis", 4 "description": "Code analysis", 5 "nodes": <nodes>, 6 "edges": <edges>, 7 "account_id": <account_id> 8}
Response body:
1{ 2 "id": <uuid> 3}
DELETE /v1/flow/:id
Description: Deletes flow
POST /v1/flow/:id/execute
Description: Executes flow
Request body:
1{ 2 <flow_parameters> 3}
Response body:
1{ 2 "id": <uuid> 3}
Materialize YAML file
POST /v1/materialize
Description: Creates or updates entities for DSL YAML files.
Request body:
1{ 2 "providers": [ 3 { 4 "id": <uuid>, 5 "name": "DevOps LLM provider", 6 "type": "openai", 7 "api_key": <api_key>, 8 "account_id": <account_id> 9 }, 10 { 11 "id": <uuid>, 12 "name": "DevOps LLM provider", 13 "type": "openai", 14 "api_key": <api_key>, 15 "account_id": <account_id> 16 } 17 ], 18 "models": [ 19 { 20 "id": <uuid>, 21 "name": "gpt-4.1", 22 "provider_id": <provider_id>, 23 "account_id": <account_id> 24 }, 25 { 26 "id": <uuid>, 27 "name": "gpt-4.1", 28 "provider_id": <provider_id>, 29 "account_id": <account_id> 30 } 31 ], 32 "tasks": [], 33 "flows": [], 34}
Response: 200 OK
Scaling
The flow-run service contains these main processes:
- DSL engine in the
/v1/materializeendpoint - Graph engine to execute flows
- Transactional Outbox engine to start graph engine and communicate with LLM provider
The DSL engine process is a development process and not a runtime process. Also, it happens very rarely in comparison to the production load, so we will not consider how to scale it because simple horizontal scaling is enough for it.
From these features I can define these scaling strategies:
Horizontal Scaling of flow-run
Loading...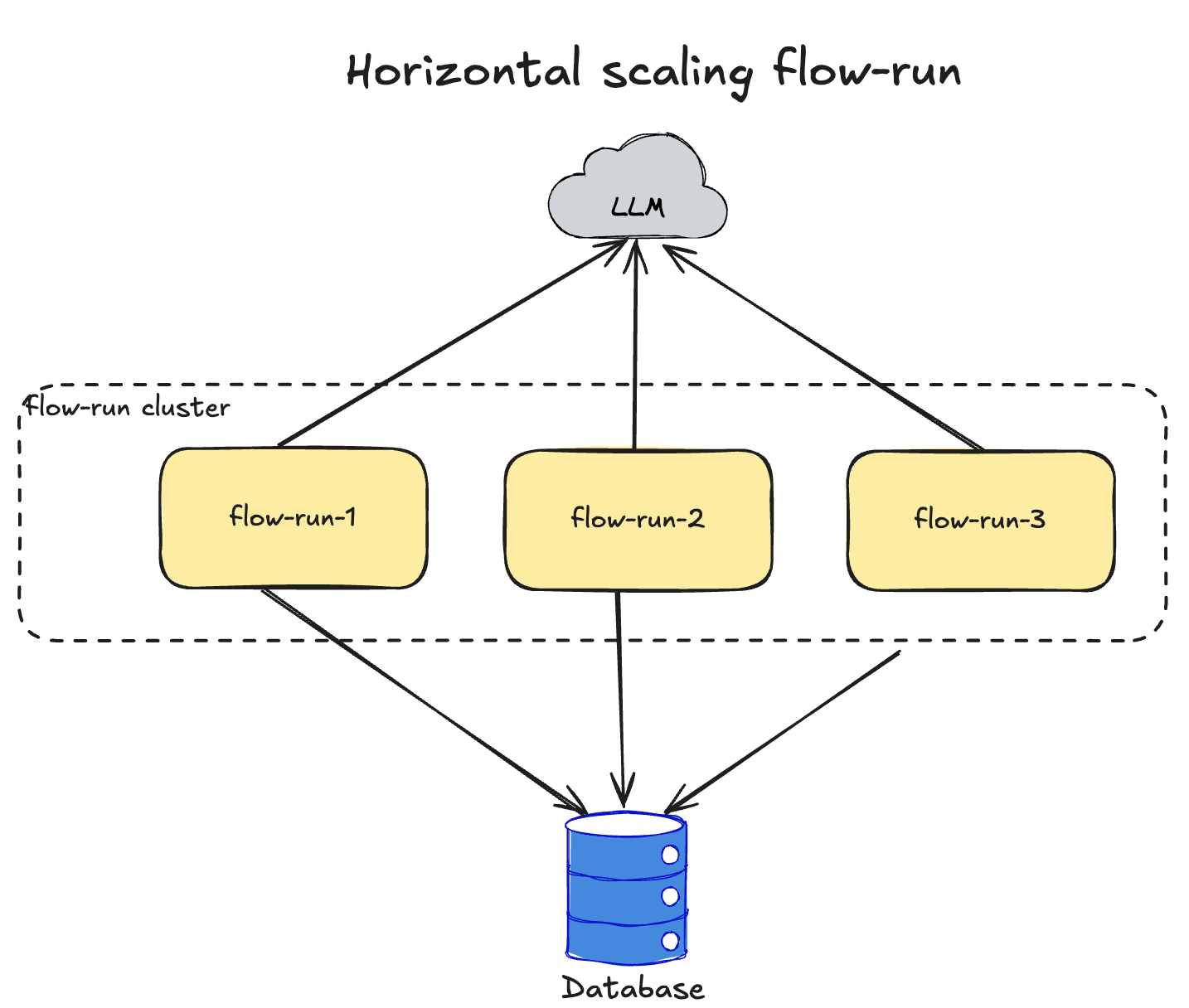
This scaling strategy may help if performance of graph engine is not enough to handle production load. Need to deploy multiple flow-run instances. Since transactional outbox pattern guarantees reading data from the database to process, load will be distributed between nodes automatically. To distribute HTTP load between nodes, need to add Load Balancer before a cluster.
Database scaling
Loading...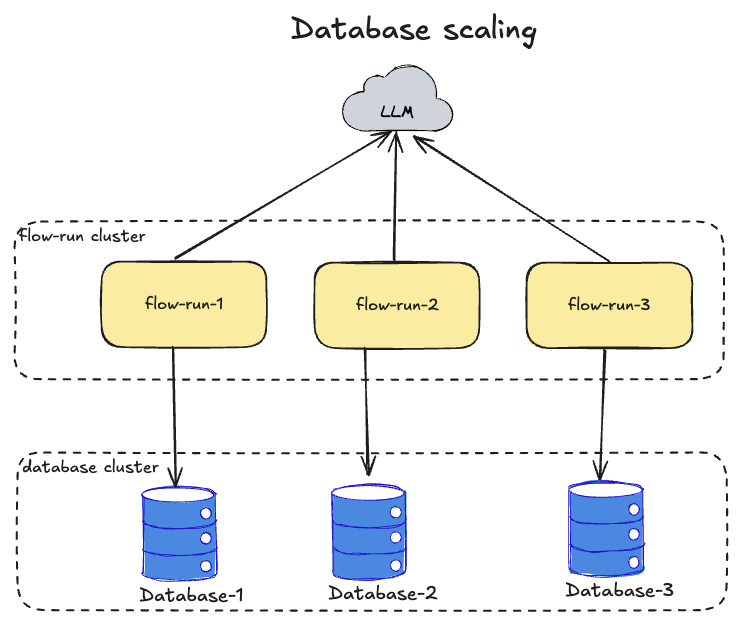
There are two strategies with database scaling:
- Master and read replicas - this is the simplest one and should be used first because the
graph enginefirst bottleneck will be for read load. When scheduler schedules a lot of graphs to execute, database will be overloaded with a lot of reads, so read replicas will solve this problem - Table partitioning - will not help here because access for the
Flowentity is always lock-free and main performance issues with write load will be with the database host resources - Database clustering - this is a more complex approach but it solves the problem with high write throughput which may happen at big scale
Multi LLM accounts
Loading...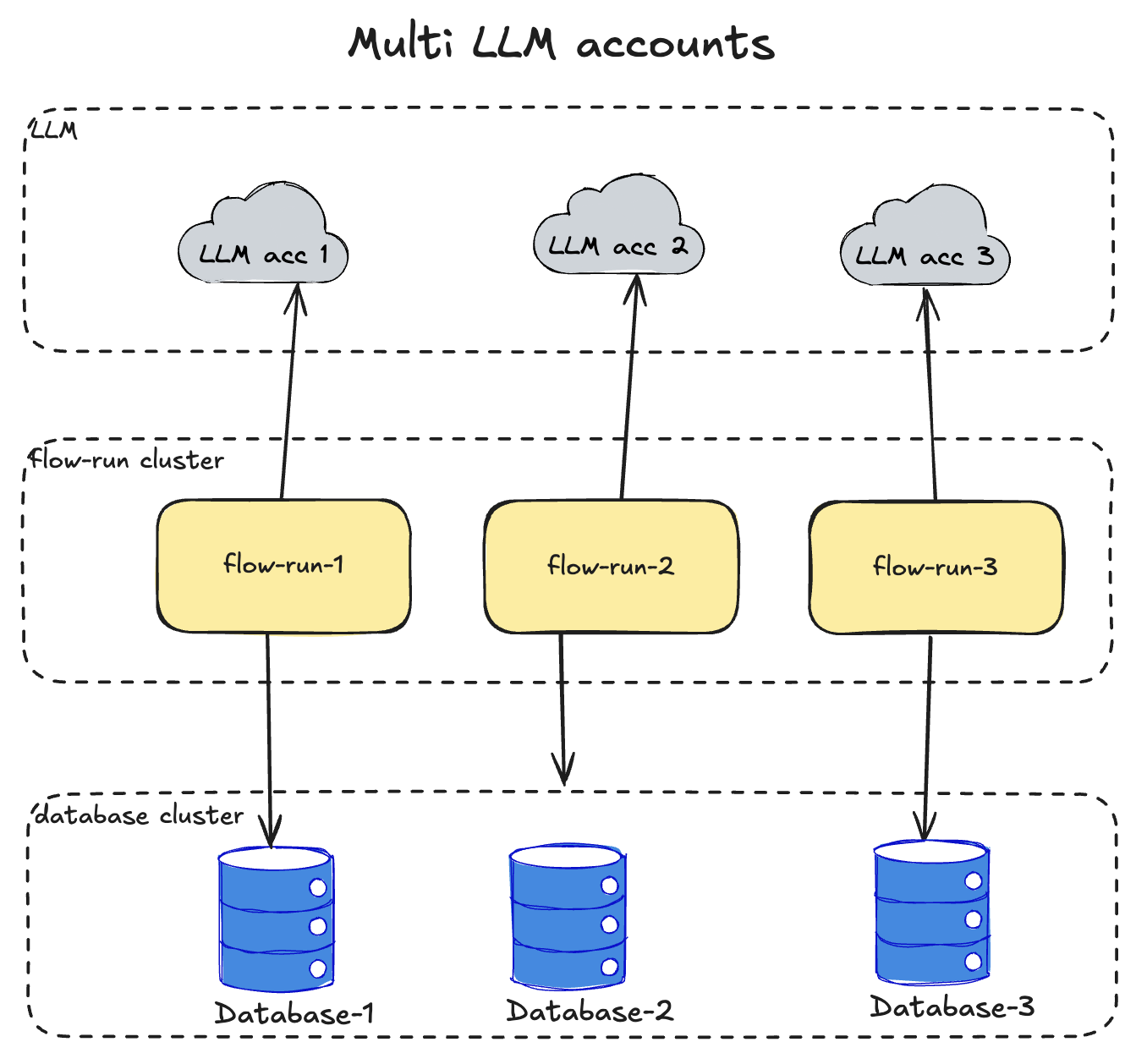
LLM integration scaling is in the grey zone because currently LLM providers apply strict restrictions for API usage. To deal with them we have these options:
- Use multiple LLM providers - use different providers for different flows/tasks. Each prompt should be developed and tested on the specific provider because changing a provider for one prompt without previous testing on it will result in unknown quality and may be bug-prone. That's why this option is good only if Prompt Developer can distinguish which prompt can be executed on which provider. But from the LLM provider terms point of view, this is the clearest approach
- Use multiple LLM provider accounts - use one LLM provider with multiple accounts. With this approach we can still use one provider but may be subject to restricted account access by LLM provider due to policy violation
The second option is simpler from the developers' point of view but riskier for business because outage may happen due to internal LLM provider investigation process. That's why I recommend using the first option which is harder at the development stage but less risky for business.
Conclusions
In this article I explained the system design for the flow-run project. In my next articles I will start service implementation and record every step with camera for my YouTube channel. Thanks for reading and see you in the next article.
Btw, during the design process for flow-run, I recorded live-design YouTube videos:
📧 Stay Updated
Get weekly insights on backend development, architecture patterns, and startup building directly in your inbox.
Free • No spam • Unsubscribe anytime
Share this article
Related articles
Fleeto Private Local IoT Control Without Cloud Infrastructure
Fleeto is a private local IoT device management platform that runs on Raspberry Pi, uses secure MQTT with mTLS, stores telemetry locally, and provides dashboards and command execution without cloud infrastructure.
flow-run: LLM Orchestration, Prompt Testing & Cost Monitoring
Open-source runner for LLM workflows: orchestrate prompts and agents, run regression tests, control costs, and publish metrics for observability and CI/CD.
