Python RAG API Tutorial with LangChain & FastAPI – Complete Guide

Introduction
During last few months I was observing new releases in AI sector and new startups which are using AI. So I was curious what they are doing? How they are doing these AI things? While I have some experience with building AI applications I feel that's it's not enough and I want to know more about building AI apps. That's why with this new blog post I'm starting a new journey in my life - blogging about software engineering.
In this blog post I will explain how to build AI powered application to chat with uploaded PDF files. It will use these techniques and frameworks:
- Retrieval Augmented Generation (RAG)
- LangChain to build RAG and communicate with OpenAI
- FastAPI to build API
- Python 😊
High Level Architecture
Loading...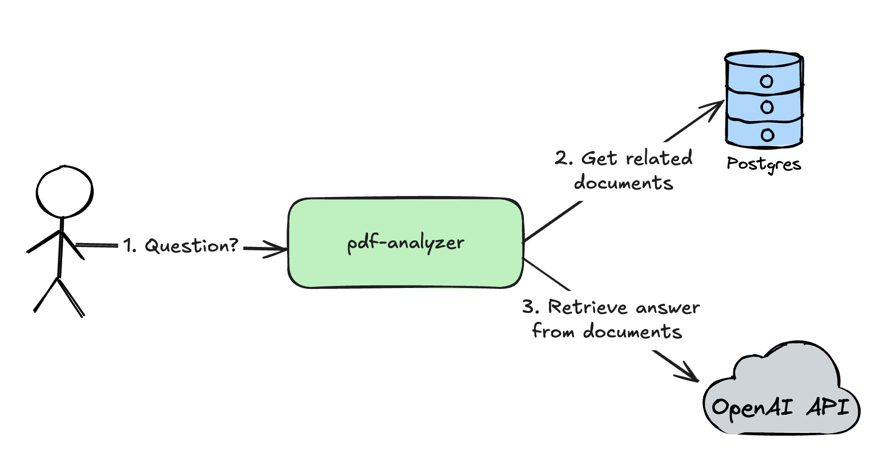
pdf-analyzer - service which analyzes PDF documents and retrieves answers for user questions from PDF documents
- User sends a question to the
pdf-analyzerservice - The
pdf-analyzerservices gets related document to a user question from the Postgres database - The
pdf-analyzersends a request with a user question and retrieved documents from the step 2 to OpenAI API to get an answer for a user question.
Before we will jump to the details of implementation let's understand why this architecture has been called "retrieval augmented generation".
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) - the pattern in AI applications in which to provide an answer for a user am application will provide related information for a user request to LLM. Which will make LLM answer more "smarter" because LLM will get more context about a problem which it should solve.
So the process of RAG the best depicts this diagram:
Loading...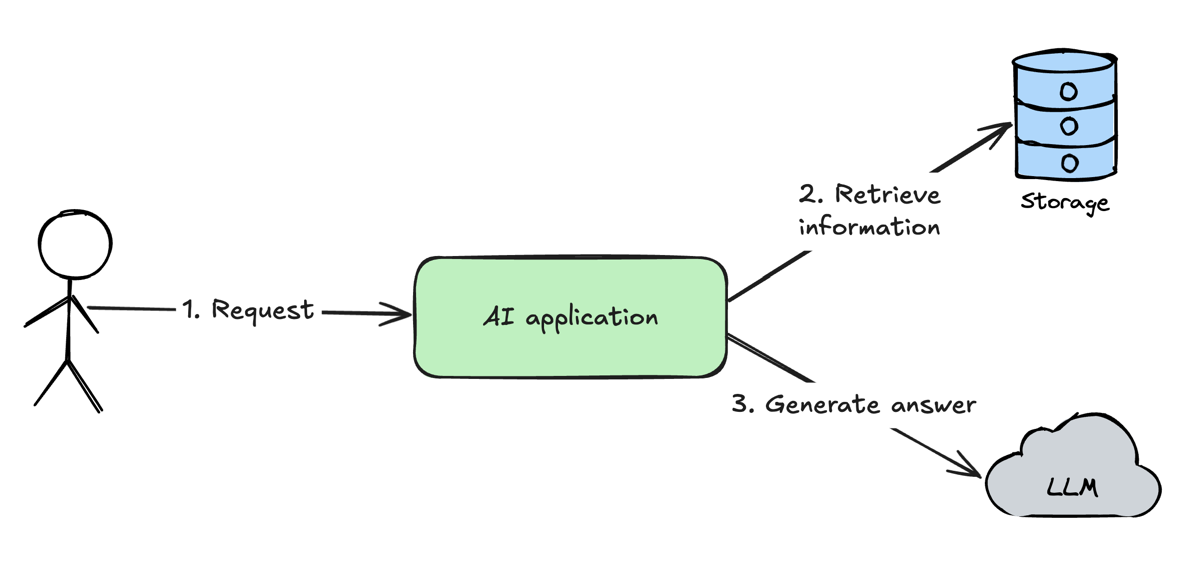
- User sends a request to AI application
- AI application retrieves information from the external storage
- AI application augments original user request with a retrieved information and sends to LLM to generate an answer
This approach results in much more better LLM responses than just directly send the document with a lot of pages to LLM and ask for a response.
Use Cases of RAG
Use case of the RAG pattern is to analyze information for cases when amount of information is higher than LLM context. While modern LLMs have huge context size RAG pattern can still be a benefit because if LLM context is filled more than 50% the chances of hallucinations are very high. So to get the best responses from LLM need to keep context usage minimal.
Use Cases of RAG in the real world
In the real world RAG can be used in these applications:
- AI Chat with company documentation
- Customer Support AI Bot
- Frequent retrieval of information from unstructured data
- Middle step of more complex flow
That's it from the theory and let's jump to the implementation part 😎
Implementation
User Flows
Upload PDF document
Loading...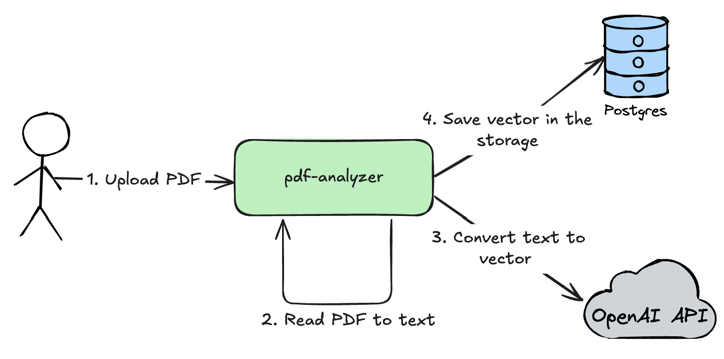
- User uploads PDF document in the
pdf-analyzerservice. - The
pdf-analyzerservice reads PDF to text, splits text by chunks to increase accuracy of data retrieval. - The
pdf-analyzerservice uses OpenAI API to convert text to a vector which will represent provided text chunk. Next we will use this vector to perform search in the database by using math. - Save vector in the storage. So at this step we are saving numeric vectors of text and the text itself in the storage. Later we will use math to find the most relevant text chunks to a user question
Chat with uploaded PDF document
Loading...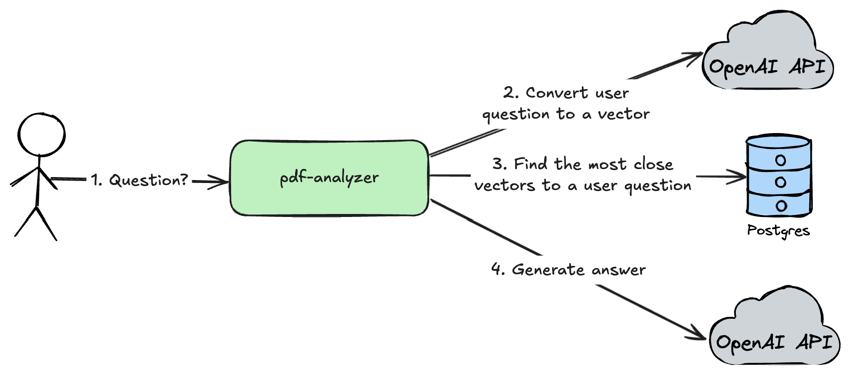
- User sends a question via API to the
pdf-analyzerservice - The
pdf-analyzerservice converts user question to a numeric vector by using OpenAI API - The
pdf-analyzerservice finds the most close vectors in the storage for a user question. - The
pdf-analyzersends user question, retrieved documents and system prompt to the OpenAI API to get the most accurate answer
Technology Decisions
By knowing user flows above we can decide what technologies we will use to build this application.
- LangChain Framework - the best framework to build AI systems which covers a lot of cases
- Python - original language for LangChain is Python, so we will go with it
- FastAPI - the modern and super convenient framework to build APIs in Python which can handle huge load. Also it allows to handle high load in Python.
- Postgres - A mature database with a support of vector storage via plugin
Service Architecture
Loading...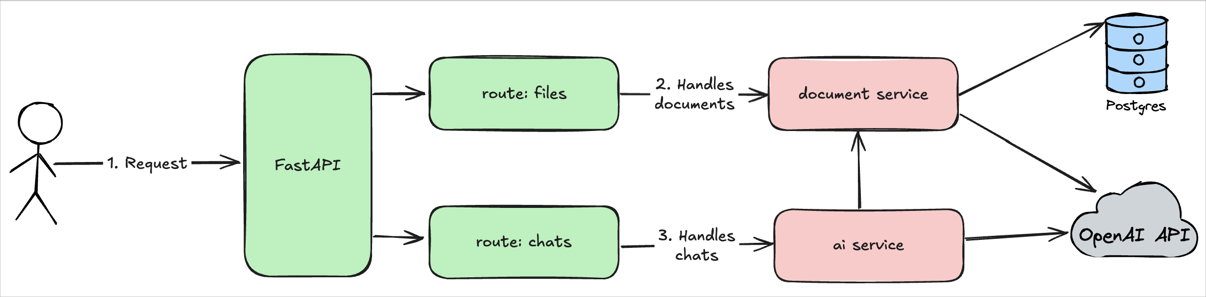
The pdf-analyzer service will use a classical layered architecture:
- Routes
filesandchatswill handle HTTP requests and use services to execute business logic - Services
document serviceandai servicewill execute business logic and integrate with Postgres and OpenAI API
This architecture approach provides a possibility to satisfy single responsibility principle and keep system simple.
The whole source code of an article is available at GitHub. For a simplicity of an article I will include only code which highlights the most important concepts of RAG API.
Implementation
Document Service
DocumentService - the service which is responsible to save/read documents.
1import tempfile 2 3from langchain_core.vectorstores import VectorStore 4from langchain_core.documents import Document 5from langchain_text_splitters.base import TextSplitter 6from pdf_analyzer.models import File 7from dataclasses import dataclass 8from sqlmodel import Session 9from langchain_community.document_loaders import PyPDFLoader 10from pdf_analyzer.repositories.file import FileRepository 11from uuid import UUID 12 13 14@dataclass 15class DocumentService: 16 17 vector_store: VectorStore 18 text_splitter: TextSplitter 19 file_repository: FileRepository 20 21 async def save(self, session: Session, file: File) -> File: 22 # 1. Save file to the database 23 file = self.file_repository.create_file(session, file) 24 25 # 2. Convert file to a list of LangChain documents 26 documents = self.__convert_to_documents(file) 27 # 3. Split list of LangChain documents to smaller documents to improve accuracy of RAG 28 all_splits = self.text_splitter.split_documents(documents) 29 # 4. Adds metadata to a file to allow communicate with specific file 30 self.__add_metadata(all_splits, file) 31 # 5. Save documents in the vector store 32 await self.vector_store.aadd_documents(all_splits) 33 34 return file 35 36 async def search(self, text: str, file_ids: list[UUID] = []) -> list[Document]: 37 documents_filter = None 38 if file_ids: 39 documents_filter = { 40 "file_id": {"$in": [str(file_id) for file_id in file_ids]} 41 } 42 return await self.vector_store.asimilarity_search(text, filter=documents_filter) 43 44 def __add_metadata(self, documents: list[Document], file: File): 45 for doc in documents: 46 doc.metadata["file_name"] = file.name 47 doc.metadata["file_id"] = str(file.id) 48 49 def __convert_to_documents(self, file: File) -> list[Document]: 50 with tempfile.NamedTemporaryFile(suffix=".pdf", delete=True) as tmp_file: 51 tmp_file.write(file.content) 52 tmp_file.flush() 53 54 loader = PyPDFLoader(tmp_file.name) 55 return loader.load()
The most interesting part of the system is this DocumentService which saves file in the database by following these steps:
- Save file to the database
- Convert file to a list of LangChain documents
- Split list of LangChain documents to smaller documents to improve accuracy of RAG
- Adds metadata to a file to allow communicate with specific file
- Save documents in the vector store
Pretty important step is step 4 because at the end our user wants to communicate with specific files and not all files in the system. That's why we are adding metadata tag file_id in the __add_metadata method.
Loading...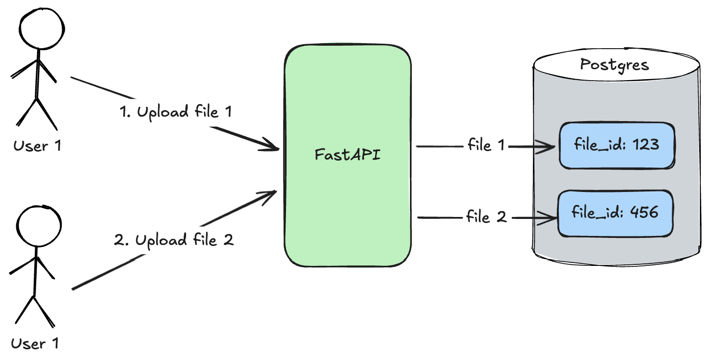
User 1uploadsfile 1and the__add_metadatamethod specifiesfile_id: 123for itUser 2uploadsfile 2and the__add_metadatamethod specifiesfile_id: 456for it
When users will search relevant content in files they will pass file_id tag which will be used to find specific files as it was done in the search method.
AI Service
AIService - the service which is responsible for OpenAI LLM API integration.
1from langchain_core.language_models import BaseChatModel 2from langchain_core.documents import Document 3from langchain_core.prompts import ChatPromptTemplate 4from pydantic import BaseModel, Field 5 6prompt_template = ChatPromptTemplate.from_messages( 7 [ 8 ( 9 "system", 10 "You are an expert extraction algorithm. " 11 "Only extract relevant information from the text. " 12 "If you do not know the value of an attribute asked to extract, " 13 "return null for the attribute's value.", 14 ), 15 ("system", "{data}"), 16 ("human", "{text}"), 17 ] 18) 19 20 21class Output(BaseModel): 22 answer: str | None = Field( 23 default=None, 24 description="Answer on the question", 25 ) 26 27 28class AIService: 29 30 def __init__(self, llm: BaseChatModel): 31 self.llm = llm 32 self.structured_llm = llm.with_structured_output(schema=Output) 33 34 def retrieve_answer(self, question: str, docs: list[Document]) -> str | None: 35 data = "\n\n".join(doc.page_content for doc in docs) 36 prompt = prompt_template.invoke({"text": question, "data": data}) 37 llm_result = self.structured_llm.invoke(prompt) 38 39 return Output.model_validate(llm_result).answer if llm_result else None 40
The retrieval of an answer from a document looks like this:
- The list of LangChain documents joins together in a string
- LangChain prompt template substitutes template variables and generates a final prompt
- LangChain llm class generates a structured response
Outputby sending my prompt to OpenAI - LLM response validates to be a valid Pydentic
Outputmodel
ChatService
ChatService - the service which is responsible for a user conversation with LLM and augmenting user requests to LLM.
1from dataclasses import dataclass 2from pdf_analyzer.schemas import ChatCreate 3from pdf_analyzer.repositories import ChatRepository, MessageRepository 4from pdf_analyzer.models import Chat, Message, SenderType 5from sqlmodel import Session, select 6from pdf_analyzer.schemas import MessageCreate 7from pdf_analyzer.services.ai import AIService 8from pdf_analyzer.services.document import DocumentService 9from uuid import UUID 10from typing import Sequence 11 12 13@dataclass 14class ChatService: 15 chat_repository: ChatRepository 16 message_repository: MessageRepository 17 ai_svc: AIService 18 document_svc: DocumentService 19 20 def create_chat(self, session: Session, chat_create: ChatCreate): 21 chat = Chat(name="New Chat", files=[]) 22 return self.chat_repository.create(session, chat, chat_create.file_ids) 23 24 def find_all_chats(self, session: Session): 25 return self.chat_repository.find_all(session) 26 27 def get_chat(self, session: Session, chat_id: UUID): 28 chat = session.exec(select(Chat).where(Chat.id == chat_id)).one_or_none() 29 if not chat: 30 raise ValueError(f"Chat with ID {chat_id} does not exist.") 31 return chat 32 33 async def send_message( 34 self, session: Session, chat_id: UUID, message_create: MessageCreate 35 ): 36 human_message = Message( 37 content=message_create.content, 38 chat_id=chat_id, 39 sender_type=SenderType.HUMAN, 40 ) 41 42 chat = self.get_chat(session, chat_id) 43 docs = await self.document_svc.search( 44 human_message.content, [file.id for file in chat.files] 45 ) 46 47 answer = self.ai_svc.retrieve_answer( 48 human_message.content, 49 docs, 50 ) 51 if not answer: 52 answer = "N/A" 53 54 ai_message = Message(content=answer, chat_id=chat_id, sender_type=SenderType.AI) 55 56 self.message_repository.save_messages(session, human_message, ai_message) 57 58 return ai_message 59 60 def find_messages(self, session: Session, chat_id: UUID) -> Sequence[Message]: 61 return self.message_repository.find_by_chat_id(session, chat_id) 62
The most interesting method is send_message which is doing:
- Gets chat by message id
- Gets documents related to a chat
- Sends a request to LLM with user request and retrieved documents
- Save user message and AI response
- Return a response to a user
Testing
0. Install dependencies
To run this project Poetry should be installed in the system.
poetry install- installs dependenciespoetry shell- uses virtualenv Python in this shell
1. Create .env file
Let's test this API by hands to see how it works. The code is available in GitHub so you can clone a repository and run code locally. Need to create .env file with specified variables:
PDF_ANALYZER_OPENAI_API_KEY- OpenAI API key.PDF_ANALYZER_DB_URL- Postgres connections string.- Specify
postgresql://root:root@localhost:5432/pdf-analyzerif you will run Postgres from thedocker-compose.yamlfile.
- Specify
2. Launch docker-compose.yaml
docker compose up -d - this will start Postgres with configured vector plugin in the Docker container.
3. Launch FastAPI server
Run this command to start FastAPI:
1fastapi dev src/pdf_analyzer/main.py
Logs will look like this:
Loading...
4. Upload a file
Open http://127.0.0.1:8000/docs#/files/upload_file_files_upload__post and upload any file. I will upload Technology Radar pdf in my example.
Loading...
5. Create a chat
Open http://127.0.0.1:8000/docs#/chats/create_chat_chats__post and create a chat with using file id received in a response after file uploading.
Loading...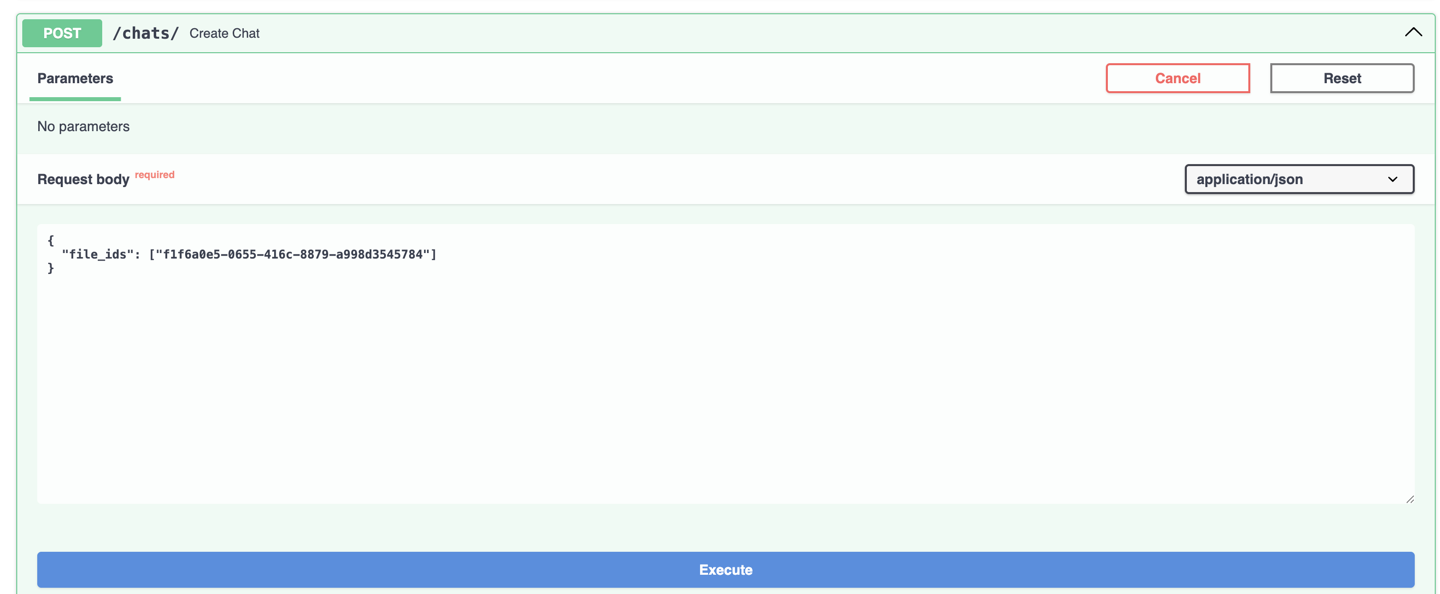
6. Send a message
Open http://127.0.0.1:8000/docs#/chats/send_message_chats__chat_id__message_post and send a message to a chat to communicate with uploaded file.
Loading...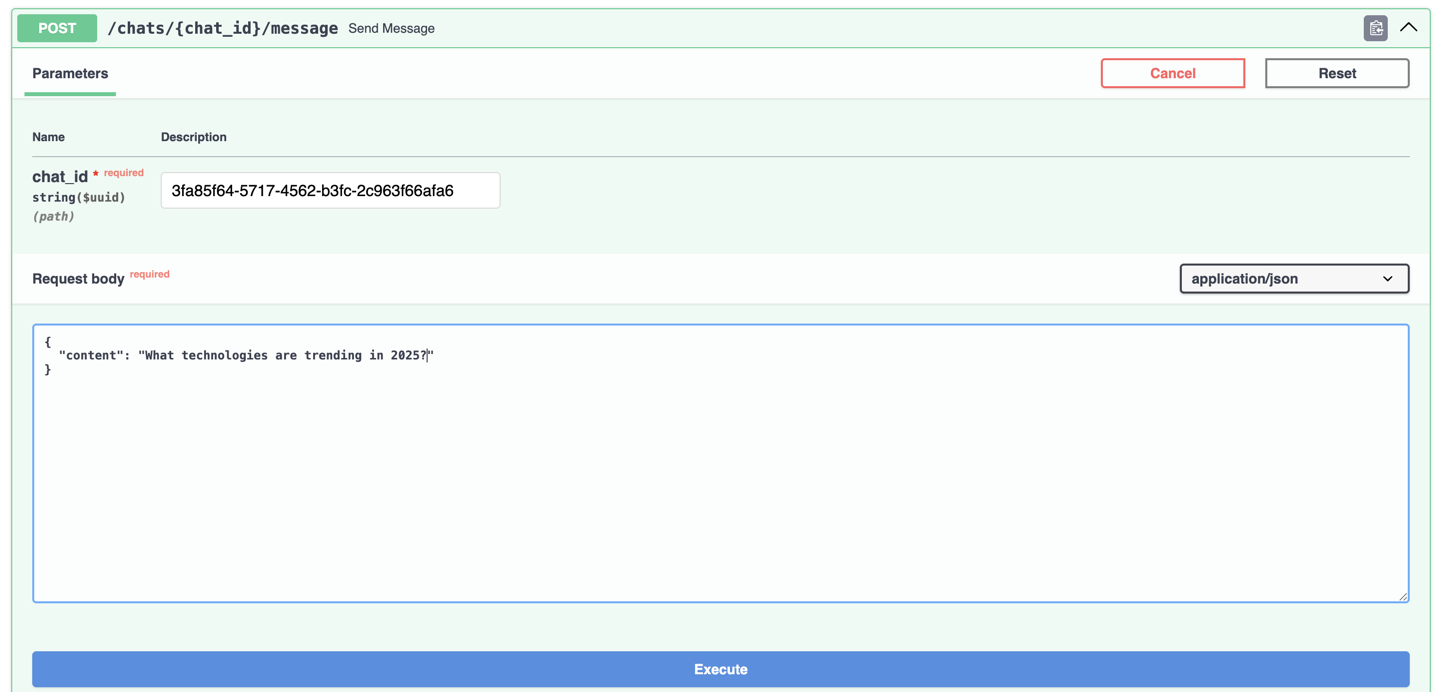
There is a response:
Loading...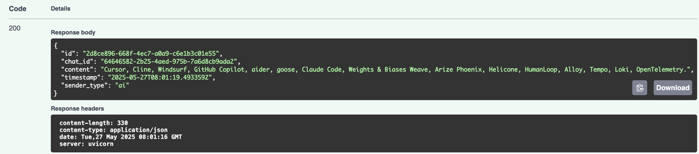
Conclusions
In this article I highlighted how to build RAG API in Python with LangChain and FastAPI. The source code is available on GitHub. This RAG technique looks useful and I will look to integrate it with some real world applications.
Just to repeate general RAG algorithm looks like this:
Loading...
📧 Stay Updated
Get weekly insights on backend development, architecture patterns, and startup building directly in your inbox.
Free • No spam • Unsubscribe anytime
Share this article
Related articles
Spec-Driven Development: How AI Coding Moves Beyond Vibe Coding
Spec-driven development turns AI coding from constant vibe coding into a structured workflow with specs, plans, tasks, and autonomous implementation.
LLM Prompt Evaluation with Python: A Practical Guide to Automated Testing
Learn how to evaluate LLM prompt quality using Python with practical examples from an open-source AI product research project. Discover automated testing techniques to ensure consistent, high-quality outputs from your AI applications while minimizing costs.
